Как я разработал промышленный контроллер + IDE + SCADA систему

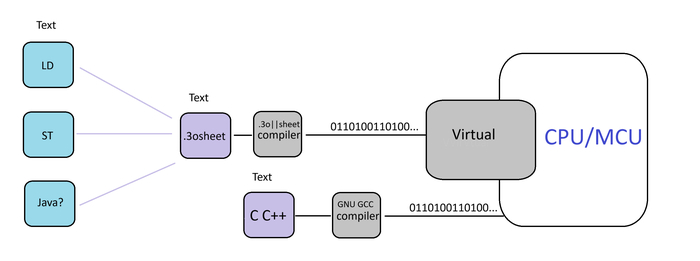
На протяжении нескольких месяцев я делюсь историей и подходами решению задач собственной разработки промышленного контроллера. Вернее - платформы для разработки ПЛК на подобии Codesys. Название моего проекта 3o|||sheet (читается как - Зошит).
Вот чтоб сразу было понятно - я не создаю физические ПЛК. Часто пишут про помехоустойчивость, Arduino/ STM32 не под 24V и прочее. Codesys - не продают ПЛК и не создают железо (насколько я знаю) это программная платформа которую устанавливают в - свое железо производители ПЛК. У меня тот же случай.
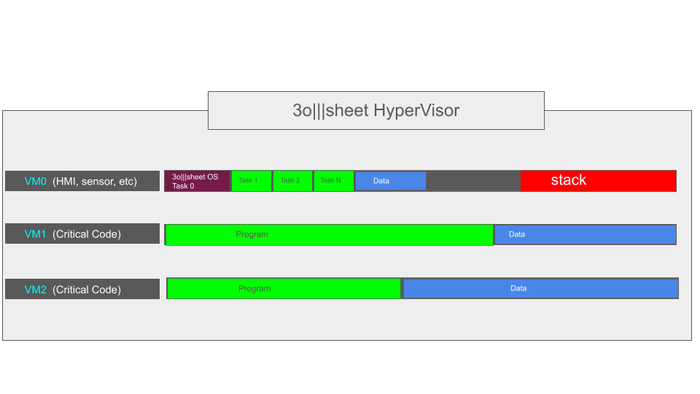
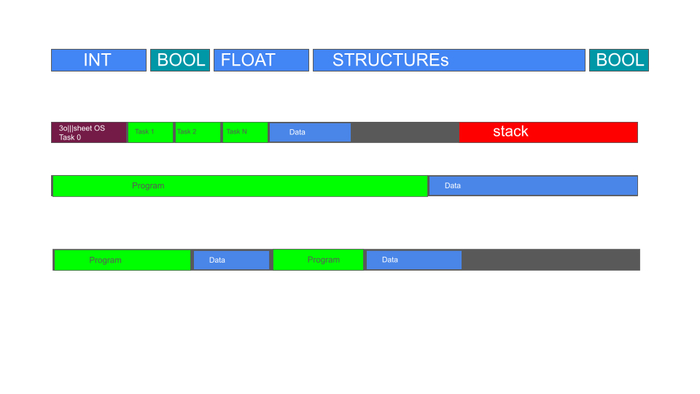
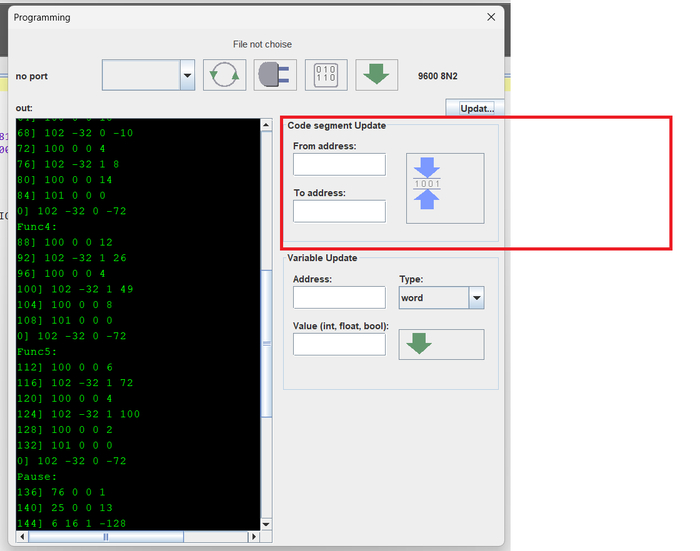
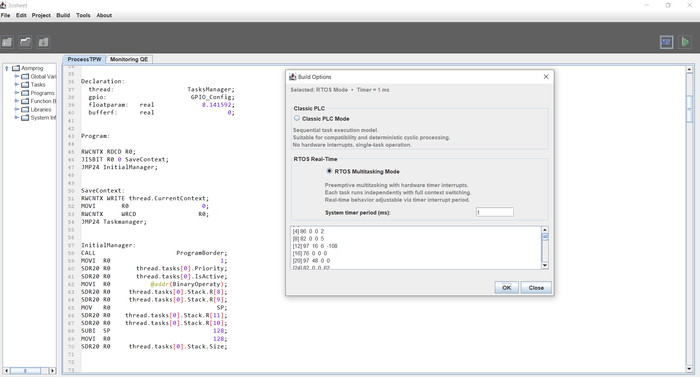
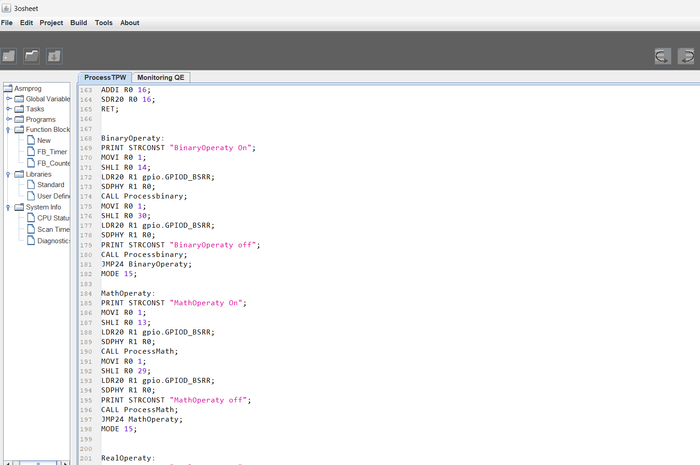
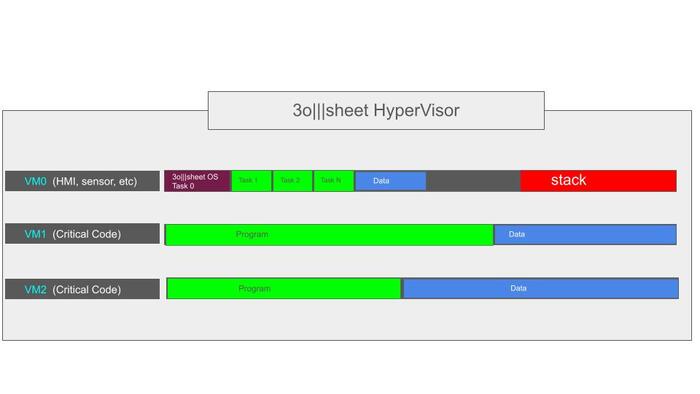
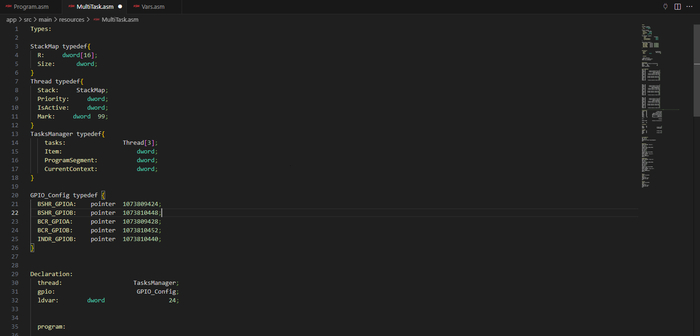
Моя разработка это: Среда IDE , с собственным графическим движком отрисовки схем. Cвой компилятор (самая сложная и умная часть). И среда выполнения на железе (самая примитивная часть - за нее все думает компилятор на этапе сборки.
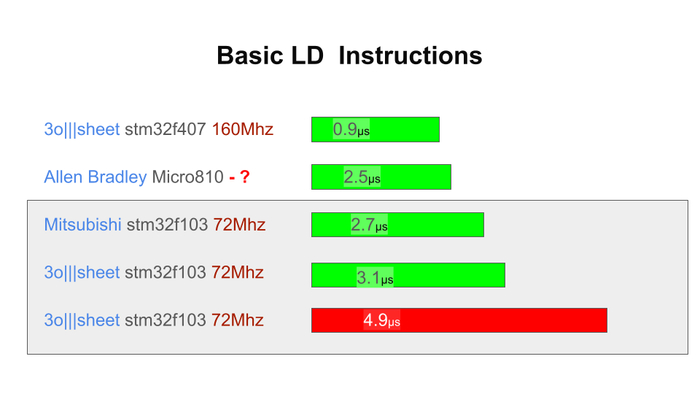
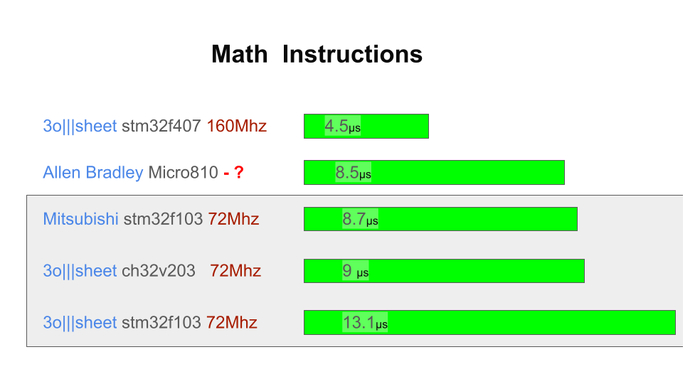
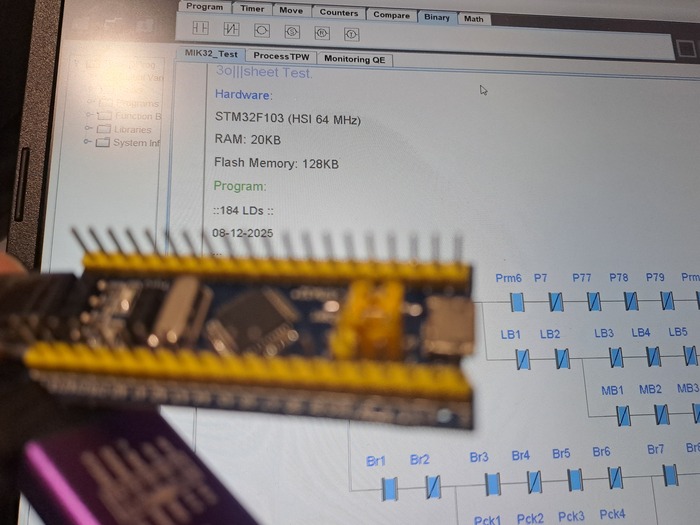
Последние тесты по производительности такого ПЛК: Разработка промышленного контроллера и среды. Оптимизация производительности STM32F103
Разрабатываю - программную часть, так как считаю что надежность и экосистема программной работы это 99% успешности проекта.
Работа до создания ПЛК и откуда истоки и идеи.
Лет 6 назад, когда работал инженером - системным программистом на крупном предприятии я и познакомился с большим производством. Большое количество угольных шахт раскиданных на многие километры. Десятки подземных комбайнов , тысячи гидравлических стоек, все это генерировало миллионы значений в сутки. Системным программистом я был плохим (вернее - системным администратором), другое дело - поиск и разработка алгоритмов по визуализации всех этих миллионов значений с OPC серверов на экране.
Gatherlog (Гезерлог)- моя SCADA и система диспетчеризации.
Стоит отметить, у меня два образования, это университет, инженерно-технический, приборостроения. И Художественный институт - живопись графика. Разработка графических визуализаций - моя естественная работа, которую я лучше знал со старта (минимум программного опыта), чем более опытные разработчики с десятками лет стажа. Все это и вылилось в в последствии разработку собственного графического движка для визуализации промышленности.
Мой проеккт Gatherlog (.Net Core) можно разделить на функционал:
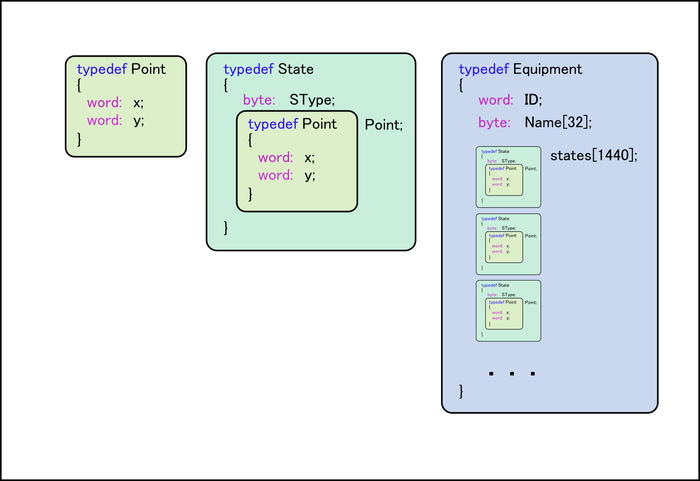
1) набор абстракций и правил, по управлению графикой - данными с оборудования. подходит дл абсолютно любого оборудования и любой сложной анимации (кроме физики конечно). Есть примитивы движений (перемещение, вращение, моргание, изменение размера, смена кадров- ваританты), комбинируя эти примитивы (как матрешку, друг в друга) можно добиться любого сложного движения. Не только анимировать шкалу деления но и сложные манипулятор роботов с любым количество состявляющих.
2) Система отчетов по работе оборудования и общих отчетов (работа/простои / обычные графики)
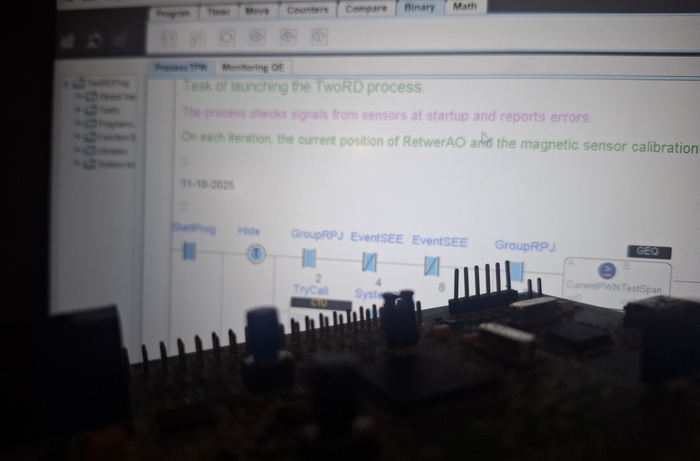
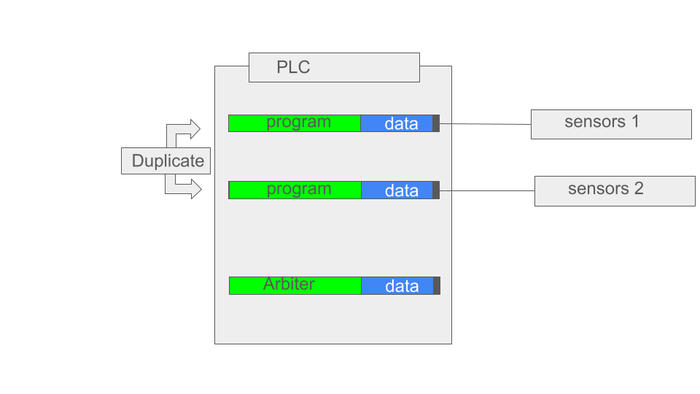
3) интерпретатор работающий в SCADA позволяющий выполнять алгоритмы написанные пользователем (то есть, превращает SCADA в серверный ПЛК). В последствии эти практики я оптимизировал до уровня микроконтроллера.
4) Работа с базами данных
Если брать WEB разработку, то сам движок реализованный так же на Javascript занимает всего лишь 500 строк кода. Хотя как то встречал компанию, которая делала визуализации, применяя полноценный игровой Unity 3D ! для подобного.
В самой первой статье по разработке ПЛК я упоминал что являюсь ценителем оптимизации, всегда искал закономерности в процессах чтоб вывести общую формулу на подобии y=x+2(sqrt(Ad^2 ... А не использовать if/else на все варианты. Поэтому, что касается логики, у меня программа всегда занимаала меньше строк кода чем у других.
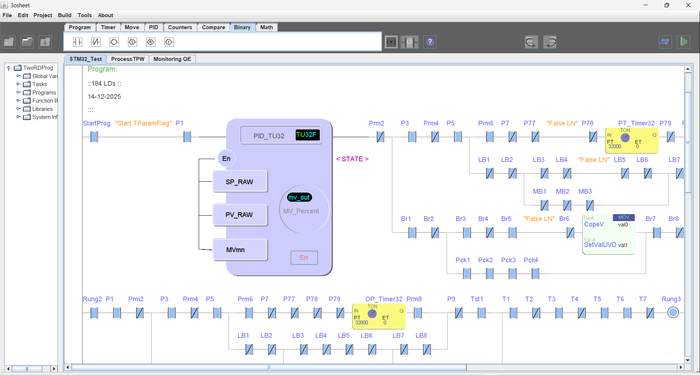
Все эти наработки и графическая библиотека в последствии перешла в нативную разработку среды программирования для ПЛК (LD FBD, схемы). А графический движок реализован на C# , Java, WinAPI, и подготавливаю его для Микроконтроллеров способного работать на небольших дисплеях.
В данном посте не все описано, но я периодически буду публиковать те или другие моменты по разработке.
И помни дорогой друг. Любая "поделка" становится "настоящей" если ее выпускает юридическое лицо. (с) Я.
Задавайте вопросы в комментариях и на почту: zoshytlogic@gmail.com