
0 просмотренных постов скрыто



Нужен совет
KUBERNETES
POD не получает IP адреса от FLANNEL
Куда копать?

kubectl logs -n kube-flannel kube-flannel-ds-k22qx
Defaulted container "kube-flannel" out of: kube-flannel, install-cni-plugin (init), install-cni (init)
I1219 15:15:42.175870 1 main.go:215] CLI flags config: {etcdEndpoints:http://127.0.0.1:4001,http://127.0.0.1:2379 etcdPrefix:/coreos.com/network etcdKeyfile: etcdCertfile: etcdCAFile: etcdUsername: etcdPassword: version:false kubeSubnetMgr:true kubeApiUrl: kubeAnnotationPrefix:flannel.alpha.coreos.com kubeConfigFile: iface:[] ifaceRegex:[] ipMasq :true ipMasqRandomFullyDisable:false ifaceCanReach: subnetFile:/run/flannel/subnet.env publicIP: publicIPv6: subnetLeaseRenewMargin:60 healthzIP:0.0.0.0 healthzPort:0 iptablesRe syncSeconds:5 iptablesForwardRules:true blackholeRoute:false netConfPath:/etc/kube-flannel/net-conf.json setNodeNetworkUnavailable:true}
W1219 15:15:42.176156 1 client_config.go:659] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I1219 15:15:42.193433 1 kube.go:139] Waiting 10m0s for node controller to sync
I1219 15:15:42.193501 1 kube.go:537] Starting kube subnet manager
I1219 15:15:43.195283 1 kube.go:163] Node controller sync successful
I1219 15:15:43.195513 1 main.go:241] Created subnet manager: Kubernetes Subnet Manager - node-01
I1219 15:15:43.195590 1 main.go:244] Installing signal handlers
I1219 15:15:43.197477 1 main.go:523] Found network config - Backend type: vxlan
I1219 15:15:43.215555 1 kube.go:737] List of node(node-01) annotations: map[string]string{"kubeadm.alpha.kubernetes.io/cri-socket":"unix:///var/run/containerd/containerd.s ock", "node.alpha.kubernetes.io/ttl":"0", "volumes.kubernetes.io/controller-managed-attach-detach":"true"}
I1219 15:15:43.215676 1 match.go:211] Determining IP address of default interface
I1219 15:15:43.219122 1 match.go:269] Using interface with name enp0s3 and address 192.168.1.100
I1219 15:15:43.219500 1 match.go:291] Defaulting external address to interface address (192.168.1.100)
I1219 15:15:43.220506 1 vxlan.go:128] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false
I1219 15:15:43.235371 1 kube.go:704] List of node(node-01) annotations: map[string]string{"kubeadm.alpha.kubernetes.io/cri-socket":"unix:///var/run/containerd/containerd.s ock", "node.alpha.kubernetes.io/ttl":"0", "volumes.kubernetes.io/controller-managed-attach-detach":"true"}
I1219 15:15:43.286824 1 kube.go:558] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.244.0.0/24]
I1219 15:15:43.294251 1 main.go:378] Cleaning-up unused traffic manager rules
I1219 15:15:43.294289 1 nftables.go:280] Cleaning-up nftables rules...
I1219 15:15:43.394848 1 iptables.go:50] Starting flannel in iptables mode...
W1219 15:15:43.394970 1 main.go:577] no subnet found for key: FLANNEL_NETWORK in file: /run/flannel/subnet.env
W1219 15:15:43.394989 1 main.go:577] no subnet found for key: FLANNEL_SUBNET in file: /run/flannel/subnet.env
W1219 15:15:43.395001 1 main.go:612] no subnet found for key: FLANNEL_IPV6_NETWORK in file: /run/flannel/subnet.env
W1219 15:15:43.395011 1 main.go:612] no subnet found for key: FLANNEL_IPV6_SUBNET in file: /run/flannel/subnet.env
I1219 15:15:43.395047 1 iptables.go:101] Current network or subnet (10.244.0.0/16, 10.244.0.0/24) is not equal to previous one (0.0.0.0/0, 0.0.0.0/0), trying to recycle ol d iptables rules
I1219 15:15:43.446141 1 iptables.go:111] Setting up masking rules
I1219 15:15:43.454166 1 iptables.go:212] Changing default FORWARD chain policy to ACCEPT
I1219 15:15:43.459792 1 main.go:467] Wrote subnet file to /run/flannel/subnet.env
I1219 15:15:43.459824 1 main.go:471] Running backend.
I1219 15:15:43.460868 1 vxlan_network.go:68] watching for new subnet leases
I1219 15:15:43.461495 1 vxlan_network.go:115] starting vxlan device watcher
I1219 15:15:43.475659 1 main.go:492] Waiting for all goroutines to exit
I1219 15:15:43.487726 1 iptables.go:358] bootstrap done
I1219 15:15:43.498797 1 iptables.go:358] bootstrap done
kubectl events -n kube-flannel kube-flannel-ds-k22qx
LAST SEEN TYPE REASON OBJECT MESSAGE
13m Normal SuccessfulCreate DaemonSet/kube-flannel-ds Created pod: kube-flannel-ds-k22qx
13m Normal Scheduled Pod/kube-flannel-ds-k22qx Successfully assigned kube-flannel/kube-flannel-ds-k22qx to node-01
13m Normal Pulling Pod/kube-flannel-ds-k22qx Pulling image "ghcr.io/flannel-io/flannel-cni-plugin:v1.8.0-flannel1"
13m Normal Pulled Pod/kube-flannel-ds-k22qx Successfully pulled image "ghcr.io/flannel-io/flannel-cni-plugin:v1.8.0-flannel1" in 4.83s (4.83s including waiting). Image size: 4924039 bytes.
13m Normal Created Pod/kube-flannel-ds-k22qx Created container: install-cni-plugin
13m Normal Started Pod/kube-flannel-ds-k22qx Started container install-cni-plugin
13m Normal Pulling Pod/kube-flannel-ds-k22qx Pulling image "ghcr.io/flannel-io/flannel:v0.27.4"
13m Normal Pulled Pod/kube-flannel-ds-k22qx Successfully pulled image "ghcr.io/flannel-io/flannel:v0.27.4" in 15.377s (15.377s including waiting). Image size: 34136824 bytes.
13m Normal Started Pod/kube-flannel-ds-k22qx Started container install-cni
13m Normal Created Pod/kube-flannel-ds-k22qx Created container: install-cni
13m Normal Pulled Pod/kube-flannel-ds-k22qx Container image "ghcr.io/flannel-io/flannel:v0.27.4" already present on machine
13m Normal Created Pod/kube-flannel-ds-k22qx Created container: kube-flannel
13m Normal Started Pod/kube-flannel-ds-k22qx Started container kube-flannel
Показать полностью
State of DevOps Russia 2025: рост зрелости команд, интеграция AI и приоритет безопасности
Команда «Экспресс 42» — консалтинговое направление компании «Флант» — представила пятое ежегодное индустриальное исследование «Состояние DevOps в России 2025». Согласно его результатам, в российском ИТ-сообществе растёт доля высокоэффективных команд, усиливается роль информационной безопасности, а использование ML/AI-инструментов становится нормой для большинства специалистов.
Исследование проведено командой «Экспресс 42» при поддержке Deckhouse, Yandex Cloud, hh.ru, Т-Банка, VK Cloud, AvitoTech, Positive Technologies, ecom.tech, «Онтико», Selectel, X5 Tech, Axiom JDK, Okko и Sk Финтех Хаба и использует результаты опроса более 3300 специалистов из России и стран СНГ.
«DevOps как методология продолжает играть важную роль в реализации технологических проектов, однако эволюционирует вместе с изменяющимся ИТ-ландшафтом — от традиционных практик CI/CD к комплексным внутренним платформам разработки (IDP), DevSecOps и интеграции ML/AI-решений в процессы разработки. Исследование позволяет понять, в каком направлении движется российский DevOps-рынок, где мы сейчас находимся и что необходимо развивать, чтобы команды и бизнес функционировали эффективнее в новых условиях», — отметил Александр Титов, генеральный директор компании «Флант» и сооснователь «Экспресс 42».
Эволюция DevOps и рост эффективности команд
Аналитики отмечают рост эффективности DevOps-команд: доля высокоэффективных (Elite) команд выросла на 4 %, High — на 2 %, при этом доля Medium-команд сократилась на 9 %. Улучшились ключевые метрики: срок поставки в Low-командах сократился до 1–3 месяцев, время восстановления в Medium-командах достигло показателя «Меньше дня», а доля неуспешных изменений в Elite-командах упала до 0–5 %.
Команды с высоким уровнем Developer Experience (DX) — то есть с понятной и удобной средой для инженеров — чаще выстраивают быстрые и качественные циклы обратной связи, снижают когнитивную нагрузку и обладают большей автономностью. Среди ключевых факторов высокого DX респонденты отметили развитую инженерную культуру, наличие инструментальной платформы, прозрачные процессы релизов и тесное взаимодействие с безопасностью и эксплуатацией.
«В рамках нашей миссии по распространению передовых практик для достижения технологического суверенитета, мы с удовольствием поддержали открытое исследование рынка DevOps от команды «Экспресс 42». DevOps-решения сегодня — это не просто набор инструментов для автоматизации, а фундаментальный принцип построения высокоэффективных ИТ-команд. Они стирают барьеры между разработкой и эксплуатацией, создавая единый жизненный цикл, в котором скорость не противоречит надежности, превращая ИТ из затратного центра в ключевой драйвер любого бизнеса. Уверен, что исследование поможет многим нашим партнерам внедрить лучшие практики, а разработчикам DevOps, DevSecOps и AIOps-инструментов - лучше понять запросы своих клиентов», - комментирует Павел Новиков, управляющий директор Центра экспертизы Фонда "Сколково"
Информационная безопасность как часть DevOps
Информационная безопасность укрепила позиции в процессах разработки. Согласно результатам исследования, 77,1 % участников используют инструменты ИБ, 75,1 % собирают метрики информационной безопасности, а у 66,8 % компаний эти инструменты уже интегрированы в пайплайны. Более того, 40 % респондентов сообщили, что безопасность встроена во все этапы DevOps-цикла — от планирования до эксплуатации.
Наиболее востребованные практики — это интеграция проверок безопасности на ранних стадиях (50 % опрошенных) и параллельная обработка задач в CI/CD (45 %). Чаще всего средства ИБ подключаются именно к системам непрерывной интеграции и доставки — такой вариант отметили 59,9 % респондентов. При этом 46,8 % используют сканеры уязвимостей в образах контейнеров, а 35,6 % — анализаторы конфигураций Kubernetes.
Однако внедрение ИБ сопряжено с вызовами: 45,5 % сталкиваются с нехваткой технической экспертизы, 42,2 % — с проблемами совместимости, а 26,8 % респондентов признают, что результаты проверок им непонятны.
«Как показывает исследование, многие компании всё ещё игнорируют вопросы безопасности разрабатываемого ПО. Знаю, что зачастую активная защита ещё вытесняет превентивные меры типа анализа кода и проведения автоматизированного анализа используемых приложений. Это один из факторов, который “расслабляет” разработчиков ПО. Однако игнорирование подхода безопасной разработки уже становится тупиковой ветвью развития для любого вендора, поскольку одним из наиболее распространённых методов атак на компании до сих пор остаётся эксплуатация уязвимостей веб-приложений (31 %). На фоне постоянно растущего числа кибератак небезопасный код уже нельзя назвать качественной разработкой», — отметила Светлана Газизова, директор по построению процессов DevSecOps и безопасности ИИ, Positive Technologies.
«40 % компаний уже интегрировали безопасность в свой DevOps-цикл. Это очевидный прогресс. Но есть тревожный сигнал: 26,8 % опрошенных говорят, что “результаты проверок им непонятны”. Это значит, что просто добавить сканер в пайплайн недостаточно. Нужно менять подход и культуру работы: делать результаты проверок прозрачными, объяснять их ценность и учить сотрудников правильно их интерпретировать», — подчеркнул Александр Ушаков, DevOps Lead, Okko.
Тренды на рынке облаков
В 2024 году среди опрошенных компаний по-прежнему популярна гибридная модель.
Что касается оценки ключевых преимуществ облачных решений, на первое место выходит повышение надёжности IT-инфраструктуры (82 % в 2024 году против 44 % в 2023 году). Второе и третье места разделяют рост масштабируемости и отказоустойчивости при увеличении трафика текущего продукта (82 %) и соответствие требованиям регулятора в области управления персональными данными (81 %).
Треть компаний используют on-premise-решения по размещению данных в локальной инфраструктуре. Также около трети использовали гибридный формат, храня часть данных в собственной локальной инфраструктуре, а часть — в облаке.
Лидером среди облачных провайдеров стал Yandex Cloud с долей в 47,4 %. На втором месте Selectel — 17,5 %. А третье место делят Cloud.ru и Amazon Web Services, которых выбрали 14,3 и 14,1 % респондентов соответственно.
«Надежность остается одним из главных критериев для бизнеса при выборе инфраструктуры. Компании выбирают облачного провайдера как стратегического партнера, с которым можно уверенно разрабатывать ИТ-продукты, усиливать информационную безопасность и внедрять искусственный интеллект. Несмотря на стремительное развитие продуктового портфеля, мы в первую очередь фокусируемся на обеспечении надёжности, производительности и бесперебойной работы сервисов облачной платформы», – рассказал Иван Пузыревский, технический директор платформы Yandex Cloud.
AI в инженерных практиках
ИИ-инструменты становятся частью повседневной работы инженеров: 71,3 % опрошенных уже используют ML/AI-решения. Более половины из них (54,1 %) отмечает рост индивидуальной эффективности, 45,6 % — командной. Чаще всего ИИ применяют для автоматической генерации кода (65,2 %), создания документации (45,5 %) и анализа кода на наличие ошибок (45,2 %). Также значительная доля респондентов использует ИИ для автоматического создания тестовых сценариев (34,3 %).
«65 % респондентов уже активно используют автоматическую генерацию кода, а 45 % отмечают значительное упрощение работы с документацией благодаря AI. Эти инструменты постепенно становятся нормой, напрямую повышая индивидуальную и командную производительность. Умение эффективно использовать эти технологии уже сейчас является решающим конкурентным преимуществом, которое будет определять успех бизнеса на ближайшие годы», — рассказал Евгений Харченко, начальник отдела развития практик в разработке и эксплуатации, Райффайзенбанк.
Внутренние платформы: автоматизация и контроль
Развитие внутренних платформ (Internal Developer Platform, IDP) остаётся одним из ключевых направлений для компаний. Наиболее важными функциями IDP респонденты назвали управление доступом пользователей (45,8 %) и возможность быстрого поиска информации (45,2 %), а основной целью развития платформ на 2025 год — автоматизацию рутинных задач.
«Internal Developer Platform (IDP) постепенно перестаёт быть нишевым инструментом и становится must-have для крупных компаний с высокой интенсивностью разработки. Сейчас мы видим, что основной спрос на IDP формируют крупные компании с большим объёмом разработки, для которых критически важны унификация процессов, контроль доступа и безопасность», — отметил Станислав Старков, руководитель направления технологической стратегии VK Cloud, VK Tech.
Отечественное ПО и гибридные решения
Продолжается переход на российское программное обеспечение и on-premise-решения. Увеличилась доля пользователей отечественных ОС, в том числе Astra Linux, РЕД ОС и «Альт», растёт использование российских дистрибутивов Kubernetes. Каждый четвёртый участник опроса использует российскую ОС как базовый образ для контейнеров, а половина компаний развёртывает оркестратор on-premise.
«Мы на своей практике видим, что востребованность запуска Kubernetes в on-premise стабильно растёт, в том числе за счёт строгих требований службы информационной безопасности и необходимости выполнения требований регуляторов. При этом стоит обратить внимание на достаточно большой процент hybrid-инсталляций, которые позволяют совместить все преимущества собственной инфраструктуры и облачного подхода. Количество запросов на подобный тип инсталляций встречается всё чаще в компаниях разных масштабов, что предъявляет в свою очередь определённые требования к Kubernetes-дистрибутиву. Необходимо, чтобы он единообразно и одинаково хорошо развёртывался и управлял инфраструктурой и в on-premise, и в облаке. Это одна из функциональных возможностей, которая если уже не является определяющей, то должна стать такой в ближайшем будущем», — рассказал Константин Аксёнов, директор департамента разработки Deckhouse, «Флант».
Аналитики отмечают, что наблюдаются устойчивое сокращение доли ручного управления инфраструктурой и рост автоматизации. Увеличивается использование CI/CD- и Observability-систем, растёт доля on-premise-инсталляций GitLab и Kubernetes. При этом заметен тренд на стандартизацию подходов к инфраструктуре и развитие внутренних инструментальных платформ.
Рынок труда: баланс спроса и предложений
Рынок труда DevOps-специалистов в России за последние три года демонстрирует высокую активность: количество вакансий на hh.ru стабильно увеличивалось в среднем на 10 % ежегодно. В 2024 году число опубликованных предложений выросло на 16 % по сравнению с 2023-м, однако в первом полугодии 2025-го зафиксировано снижение — на 26 % относительно прошлого года.
При этом предложение со стороны специалистов продолжает расти: за 2022–2024 годы на hh.ru размещено на 72 % больше резюме, чем в предыдущем трёхлетнем периоде. Количество вакансий, опубликованных суммарно за первое полугодие, превысило количество резюме всего на 18 %. Это минимальный разрыв за последние годы, что свидетельствует о снижении дефицита кадров и росте зрелости индустрии.
«Согласно hh.индексу, в сфере ИТ в целом наблюдается высокий уровень конкуренции соискателей. В августе 2024 года индекс составлял 7,7, а к августу 2025 года вырос до 14,9. Это подтверждает тенденцию работодателей тщательно подходить к найму сотрудников и в сегменте DevOps», — отметила Мария Игнатова, директор по исследованиям, hh.ru.
Итоги и тенденции развития
В целом по итогам исследования State of DevOps Russia 2025 можно сделать вывод, что российский рынок DevOps вышел на этап устойчивого развития. Компании усиливают фокус на эффективности, безопасности и автоматизации, активно интегрируют ML/AI-инструменты и развивают внутренние платформы для ускорения релизов и повышения прозрачности процессов. Продолжается переход на отечественные решения: растёт использование российских операционных систем и дистрибутивов Kubernetes, увеличивается доля on-premise-инсталляций и инструментов на базе открытого кода.
«Российский рынок ПО продолжает идти своим, местами парадоксальным путём: с одной стороны — жёсткое внешнее давление, с другой — необратимое взросление ИТ-ландшафта. В XL-сегменте тренд на интеграцию AI в производственные конвейеры только усилился. “Бигтехи” уже отстроили безопасные внутренние платформы, а теперь метят в AIOps и GenAI-копилотов, выжимая из DevOps максимум продуктивности. Средние и мелкие компании, пережившие кадровую турбулентность 2022 года, почти повсеместно выбрали проверенный OSS-стек — GitLab, Ansible, ELK, Kubernetes. Теперь к нему добавляются отечественные надстройки — от SCA-плагинов с ГОСТ-крипто до репозиториев кода вроде GitFlic. В результате рынок движется к гибридной модели — OSS-база плюс локальные специализированные модули, что и станет реалистичным сценарием 2025–2027 годов», — отметил Дмитрий Гаевский, Technical CPO, Т-Банк.
Об исследовании
«Состояние DevOps в России» — ежегодное индустриальное исследование, которое проводит команда «Экспресс 42» в России и странах СНГ. В исследовании отслеживается распределение организаций по профилям эффективности, определяются факторы, влияющие на эффективность, оценивается развитие инженерных практик. Целевая аудитория исследования — специалисты и руководители, которые тесно связаны с разработкой, тестированием и эксплуатацией программного обеспечения. Для поиска респондентов используется метод «снежного кома»: опрос с помощью рассылок по электронной почте, социальных сетей и маркетинговых кампаний. Это позволяет получить достаточно разнотипную исходную выборку.
Показать полностью

Cilium как универсальный компонент Kubernetes-инфраструктуры: от CNI до Service Mesh
Всем привет! На связи Алексей Баранович, сегодня я хочу вам рассказать о Cilium.
В современных Kubernetes-платформах стремление к упрощению архитектуры и снижению числа зависимостей становится всё более актуальным. Особенно это заметно при построении MVP-решений или управляемых платформ, где каждый дополнительный компонент — это не только рост сложности, но и увеличение поверхности для потенциальных сбоев и уязвимостей. В этом контексте Cilium выделяется как один из немногих проектов, способных заменить сразу несколько традиционных инструментов: CNI-плагин, Ingress-контроллер, Service Mesh и даже внешний LoadBalancer. Давайте разберёмся, как это работает и почему Cilium может стать единственным «сетевым» компонентом в вашем кластере.
Cilium как CNI: основа всего
Изначально Cilium позиционировался как высокопроизводительный CNI-плагин, использующий eBPF (extended Berkeley Packet Filter) вместо iptables или IPVS. Это даёт не только значительный прирост производительности, но и гибкость на уровне ядра Linux: политики сети, observability, балансировка трафика — всё это реализуется без перезаписи цепочек правил или установки дополнительных прокси.
Но Cilium быстро вырос за рамки CNI. Сегодня он предлагает полноценную платформу для сетевой и сервисной безопасности, объединяя в себе функциональность, которая раньше требовала развёртывания десятков отдельных компонентов.
Установка Cilium через Helm
Самый распространённый способ установки Cilium — через Helm. Сначала добавьте официальный репозиторий:
helm repo add cilium https://helm.cilium.io/
helm repo update
Затем установите с базовыми настройками (для большинства сред подойдёт):
helm install cilium cilium/cilium \
--namespace kube-system \
--set ipam.mode=kubernetes
Если вы хотите использовать собственный Pod CIDR (например, 10.224.0.0/13), как часто делают в on-prem:
helm install cilium cilium/cilium \
--namespace kube-system \
--set ipam.mode=cluster-pool \
--set ipam.operator.clusterPoolIPv4PodCIDRList="{10.224.0.0/13}" \
--set ipam.operator.clusterPoolIPv4MaskSize=22 \
--set ipv4NativeRoutingCIDR=10.224.0.0/13 \
--set routingMode=native \
--set autoDirectNodeRoutes=true
Эти параметры включают режим cluster-pool для IPAM и native routing через eBPF, что даёт максимальную производительность без kube-proxy.
Встроенный LoadBalancer без MetalLB или облачных провайдеров
Одна из самых болезненных тем в on-prem Kubernetes — отсутствие встроенного решения для внешнего LoadBalancer. Обычно приходится ставить MetalLB, использовать внешние балансировщики или обходиться NodePort.
Cilium решает эту проблему с помощью BGP-интеграции и DSR (Direct Server Return). Начиная с версии 1.13, Cilium поддерживает собственный L2 и BGP-режимы для сервисов типа LoadBalancer, что позволяет:
Назначать внешние IP-адреса сервисам без MetalLB.
Работать в bare-metal и виртуальных средах (включая VMware).
Использовать DSR для минимизации latency и снижения нагрузки на worker-ноды.
Чтобы включить встроенный LoadBalancer через Helm:
helm install cilium cilium/cilium \
--namespace kube-system \
--set loadBalancer.mode=dsr \
--set loadBalancer.acceleration=native \
--set loadBalancer.serviceTopology=true
Если вы используете BGP, добавьте:
--set loadBalancer.mode=bgp \
--set loadBalancer.bgp.announce=pool
И определите IP-пул в ConfigMap или через Helm-параметры, например:
--set loadBalancer.ipam.kubernetes.serviceIPBlocks="{192.168.10.0/24}"
Теперь любой Service с типом LoadBalancer автоматически получит IP из этого пула.
Gateway API: единая модель для Ingress и Egress
Традиционные Ingress-контроллеры (Nginx, Traefik, HAProxy) требуют отдельного развёртывания, настройки TLS, rate limiting, WAF и т.д. Cilium предлагает нативную поддержку Kubernetes Gateway API — современного стандарта управления трафиком, который заменяет устаревший Ingress API.
Чтобы включить Gateway API в Cilium, достаточно установить:
helm install cilium cilium/cilium \
--namespace kube-system \
--set gatewayAPI.enabled=true
После этого вы можете создавать ресурсы Gateway, HTTPRoute и другие. Пример Gateway:
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: public-gateway
namespace: default
spec:
gatewayClassName: cilium
listeners:
- name: http
port: 80
protocol: HTTP
И HTTPRoute:
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: my-app-route
namespace: default
spec:
parentRefs:
- name: public-gateway
rules:
- matches:
- path:
type: PathPrefix
value: /api
backendRefs:
- name: my-app
port: 8080
Всё это работает без sidecar-прокси, благодаря eBPF и L7-парсингу на уровне ядра.
Service Mesh без Istio: Cilium + Envoy (опционально)
Istio — мощный, но тяжёлый Service Mesh. Он требует внедрения sidecar-прокси (Envoy) в каждый под, что увеличивает потребление ресурсов и усложняет отладку.
Cilium предлагает альтернативу: Cilium Service Mesh. Он реализует ключевые функции Service Mesh:
mTLS между сервисами (на основе SPIFFE/SPIRE или собственного PKI).
L7-наблюдаемость (HTTP, gRPC, Kafka).
Трассировка (через OpenTelemetry).
Retry, timeout, circuit breaking — через Envoy только при необходимости.
Чтобы включить базовые функции Service Mesh через Helm:
helm install cilium cilium/cilium \
--namespace kube-system \
--set l7Proxy=true \
--set hubble.enabled=true \
--set hubble.relay.enabled=true \
--set hubble.ui.enabled=true \
--set securityContext.capabilities.ciliumAgent="{CHOWN,KILL,NET_ADMIN,NET_RAW,IPC_LOCK,SYS_ADMIN,SYS_RESOURCE,DAC_OVERRIDE,FOWNER,SETGID,SETUID}"
Для mTLS:
--set encryption.enabled=true \
--set encryption.type=wireguard
Или для TLS на уровне сервисов:
--set serviceMesh.enabled=true
Если нужны продвинутые L7-политики с Envoy:
--set envoy.enabled=true
При этом sidecar не обязателен: базовые функции (шифрование, политики, метрики) работают через eBPF. Envoy подключается лишь тогда, когда нужны продвинутые L7-фичи. Это даёт гибкость: вы получаете Service Mesh без накладных расходов там, где он не нужен.
Cluster Mesh: много-кластерная сеть «из коробки»
Если у вас несколько Kubernetes-кластеров (например, dev/stage/prod или multi-region), традиционно для их объединения требуются сложные решения: submariner, istio multi-cluster, custom overlay-сети.
Cilium предлагает Cluster Mesh — встроенную возможность объединять кластеры в единую логическую сеть:
Сервисы из одного кластера доступны в другом по DNS-имени.
Единые сетевые политики применяются кросс-кластерно.
Поддержка identity-based security (не привязка к IP!).
Для включения Cluster Mesh нужно:
Установить Cilium в каждом кластере с уникальным cluster.id и cluster.name.
Настроить общий etcd или использовать clustermesh-apiserver.
Пример установки с поддержкой Cluster Mesh:
helm install cilium cilium/cilium \
--namespace kube-system \
--set cluster.name=cluster-a \
--set cluster.id=1 \
--set clustermesh.enabled=true \
--set clustermesh.useAPIServer=true
Затем выполнить настройку связи между кластерами с помощью cilium-cli:
cilium clustermesh enable --context cluster-a
cilium clustermesh enable --context cluster-b
cilium clustermesh connect cluster-a cluster-b
После этого сервисы автоматически станут доступны через DNS вида <service>.<namespace>.svc.clusterset.local.
Заключение
Cilium — это не просто CNI. Это единая платформа для всего сетевого стека Kubernetes, которая позволяет отказаться от Nginx Ingress, MetalLB, Istio и даже внешних балансировщиков в большинстве сценариев. Для инженеров, строящих управляемые, безопасные и минималистичные Kubernetes-платформы, Cilium становится не просто выбором, а стратегическим решением.
Если вы стремитесь к «меньше компонентов — больше контроля», Cilium стоит рассмотреть уже сегодня.
Показать полностью
Talos OS — способ сделать Kubernetes безопасным
Привет, друзья! Меня зовут Алексей Баранович, и сегодня я хочу рассказать о системе, которая кардинально изменила мой подход к развёртыванию и управлению Kubernetes — Talos Linux. Это не просто «ещё одна лёгкая ОС». Talos — это операционная система, спроектированная исключительно для Kubernetes, с философией иммутабельности, безопасности и полной автоматизации. Давайте разберёмся, почему он действительно крут — и что он умеет «из коробки».
Talos Linux: Kubernetes-нативная ОС нового поколения
Talos Linux — это open-source операционная система, разработанная компанией Sidero Labs, которая полностью отказывается от традиционных концепций Linux-дистрибутивов. В Talos нет:
пакетного менеджера (apt, yum, dnf);
shell-доступа (даже для root);
SSH-сервера;
возможности редактировать файлы вручную после загрузки.
Всё управление происходит через единый gRPC API, защищённый mTLS, и утилиту командной строки talosctl.
Иммутабельность и безопасность как основа
Корневая файловая система Talos монтируется только для чтения. Это означает:
Невозможно случайно или злонамеренно изменить системные файлы.
Все обновления — атомарные: система загружается либо полностью новой версией, либо откатывается.
Минимальная поверхность атаки: в образе нет интерпретаторов (Python, Bash), ненужных библиотек или демонов.
Даже диагностика не требует shell: для просмотра логов, состояния сервисов или ядра используется утилита osctl, работающая поверх API.
Декларативная конфигурация: один YAML на всё
Вся конфигурация Talos задаётся в одном файле — machine.yaml. Он описывает:
тип ноды (control plane или worker);
сетевые настройки;
параметры времени и сертификатов;
статические поды (если нужны);
настройки kubelet и kube-proxy.
Пример минимальной конфигурации control plane:
version: v1alpha1
machine:
type: controlplane
token: supersecret
ca:
crt: LS0t...
key: LS0t...
cluster:
id: my-cluster
controlPlane:
endpoint: https://192.168.1.10:6443
Этот файл передаётся ноде при загрузке (через cloud-init, ISO, PXE и т.д.) и не может быть изменён вручную — только через обновление через talosctl apply.
Сетевая подсистема: что есть «из коробки»?
Важный момент: Talos не включает CNI по умолчанию. Однако он нативно поддерживает Flannel как встроенный CNI-плагин. Это означает, что при указании:
cluster:
network:
cni:
name: flannel
Flannel будет автоматически развёрнут как часть bootstrap-процесса — без необходимости применять манифесты вручную.
Если вы хотите использовать другой CNI (Calico, Cilium, Weave и т.д.), его нужно устанавливать вручную после инициализации кластера, например, через kubectl apply или Helm. Talos не навязывает выбор — он даёт вам чистую, предсказуемую основу.
Полный жизненный цикл кластера — без ручного вмешательства
Talos управляет не только запуском Kubernetes, но и всем его жизненным циклом:
Инициализация кластера: talosctl bootstrap — инициирует etcd и control plane.
Обновление ОС и Kubernetes: через talosctl upgrade — с возможностью отката.
Резервное копирование etcd: talosctl etcd backup — создаёт снапшоты etcd.
Восстановление из бэкапа: talosctl etcd restore.
Безопасное удаление нод: talosctl reset — полностью очищает ноду.
Всё это работает без shell, без SSH, без риска человеческой ошибки.
Локальная разработка и тестирование
Хотите попробовать Talos? За пару минут можно развернуть кластер на своём ноутбуке:
talosctl cluster create --nodes 3 --controlplanes 1
Это запустит виртуальные машины через QEMU или Docker (в зависимости от ОС), настроит сеть и выдаст готовый kubeconfig.
Почему Talos — это прорыв?
Предсказуемость: все ноды идентичны, конфигурация декларативна.
Безопасность: нет shell, нет пакетов, только необходимый минимум.
Автоматизация: всё через API, идеально для GitOps и CI/CD.
Сертификация: Talos прошёл официальные тесты CNCF Kubernetes Conformance.
Полезные ссылки
CLI-инструменты: talosctl
Заключение
Talos Linux — это не просто инструмент, а новая парадигма управления инфраструктурой. Он убирает всё лишнее, оставляя только то, что нужно для надёжного и безопасного запуска Kubernetes. Если вы устали от «снежинок-серверов», ручных правок и нестабильных обновлений — пришло время попробовать Talos.
Удачи в автоматизации, и пусть ваши кластеры будут иммутабельными!
Показать полностью


Типовая архитектура

Показать полностью
1

Kubernetes в продакшене: основные понятия и вопросы на собеседовании
Меня зовут Александр, я CTO компании AppFox. Мы более 10 лет занимаемся заказной разработкой и также имеем собственные продукты.
В этой статье мы рассмотрим, что такое Kubernetes, в каких случаях его использование оправдано, и разберем вопросы, которые вы можете встретить на собеседованиях.

Что такое Kubernetes простыми словами?
Разберем на примере интернет-магазина с тремя серверами:
Сервер №1 – основной (принимает заказы).
Сервер №2 – база данных (хранит товары и пользователей).
Сервер №3 – бекенд для API (обрабатывает платежи).
Проблема:
В Чёрную пятницу приходит в 10 раз больше покупателей. В результате, сервера №1 и №3 падают от нагрузки, магазин "висит".
Сервер №2 (база данных) ломается, а все заказы теряются.
Чтобы добавить новые сервера, админ вручную копирует настройки, что занимает часы.
Решение при помощи Kubernetes.
Те же 3 сервера, но теперь они управляются Kubernetes.
Автомасштабирование
При наплыве покупателей Kubernetes автоматически запускает дополнительные копии серверов №1 и №3.
Когда нагрузка падает – лишние сервера отключаются.
Отказоустойчивость
Если сервер №2 (база данных) упал, Kubernetes сразу переключает нагрузку на его резервную копию.
Покупатели даже не замечают проблемы.
Гибкие обновления
Вы хотите обновить API (сервер №3).
Kubernetes делает это без downtime:
Запускает новые версии API, переключает трафик на них и останавливает старые.
Экономия денег
Ночью, когда магазин почти не используют, Kubernetes отключает часть серверов.
Утром – снова включает.
Что это даёт бизнесу?
Магазин не "падает" в пиковые нагрузки (Чёрная пятница, распродажи).
Нет потери заказов – если что-то сломалось, система сама всё починит.
Быстрые обновления – можно выпускать новые фичи без остановки магазина.
Экономия на серверах – не нужно держать "лишние" мощности.
Kubernetes: мощный инструмент, но не серебряная пуля
Kubernetes — это система оркестрации контейнеров, которая помогает управлять масштабируемыми и отказоустойчивыми приложениями.
Термин k8s является синонимом Kubernetes и означает 8 букв между первой и последней буквой. Да, программисты любят сокращения :)
Примерно с 2018 года мы наблюдаем устойчивый тренд: Kubernetes стал синонимом «правильной» продакшн-инфраструктуры. И это не случайно. Он действительно решает множество проблем, связанных с управлением микросервисами, масштабированием, отказоустойчивостью и обновлением без простоев.
Когда Kubernetes оправдан:
Микросервисная архитектура с большим количеством сервисов.
Необходимость автоматического масштабирования под нагрузку.
Высокие требования к отказоустойчивости.
Гибкость деплоя (Canary, Blue-Green, A/B-тестирование).
Когда Kubernetes — избыточное решение:
Монолитное приложение с низкой нагрузкой.
Маленькие проекты без потребности в масштабировании.
Стартапы с ограниченным бюджетом.
Проект для демо или MVP, в которых планируется масштабирования только после получения инвестиций
Команда не готова к сложности k8s (обучение и поддержка требуют ресурсов).
В компании AppFox мы используем Kubernetes при построения кластеров для мультиплеерных игр и проектов со сложной микросервисной архитектурой. В частности, мы его использовали при разработке решений для СберБанка и Банка ВТБ.
Основные понятия Kubernetes
Pod — минимальная единица развертывания (может содержать один или несколько контейнеров).
Deployment — декларативное описание желаемого состояния приложения.
Service — абстракция для доступа к подам (ClusterIP, NodePort, LoadBalancer).
Ingress — управление внешним трафиком (роутинг, SSL).
ConfigMap & Secret — хранение конфигураций и чувствительных данных.
PersistentVolume (PV) & PersistentVolumeClaim (PVC) — работа с постоянным хранилищем.
Helm — менеджер пакетов для k8s (чарты).
Вопросы по Kubernetes на собеседовании
Теперь самое интересное — какие вопросы задают кандидатам в зависимости от их уровня.
Для backend-разработчика
Что такое контейнер и зачем нужен Docker?
Контейнер - это изолированное окружение для запуска приложений со всеми зависимостями.
Docker - платформа для создания и управления контейнерами.
Разница между Docker и Kubernetes
Docker создает контейнеры
Kubernetes управляет множеством контейнеров на разных серверах.
Как работает kubectl get pods? Что выведет эта команда?
Команда показывает список подов (pods) - минимальных единиц развертывания в k8s. Вывод включает имя пода, статус, количество рестартов и возраст.
Что такое Deployment и зачем он нужен?
Это объект k8s для декларативного управления подами. Позволяет:
Разворачивать приложения
Обновлять их (rolling update)
Возвращаться к предыдущим версиям (rollback)
Масштабировать количество реплик
Как приложение в k8s получает конфигурацию (ConfigMap, Secrets)?
ConfigMap хранит конфигурации (например, настройки приложения)
Secrets - чувствительные данные (пароли, токены). Они монтируются в поды как файлы или переменные окружения.
Что такое Pod, Deployment и Service?
Pod — это минимальная единица в Kubernetes
Deployment управляет жизненным циклом Pod'ов
Service предоставляет сетевой доступ.
Как подать переменные окружения в Pod?
Через env, envFrom, ConfigMap, Secret.
Что произойдет, если Pod упал?
Kubernetes сам его перезапустит — важно понимать работу контроллеров.
Для Junior DevOps
Как создать под с помощью kubectl?

Как посмотреть логи пода?

Как работает Service? Какие типы сервисов знаете?
Абстракция для доступа к набору подов. Типы:
ClusterIP (внутренний IP)
NodePort (порт на каждой ноде)
LoadBalancer (внешний балансировщик)
ExternalName (CNAME-запись)
Как обновить приложение в k8s (стратегии деплоя)?
RollingUpdate (постепенная замена подов)
Recreate (удаление всех старых перед созданием новых)
Что делает kubelet и kube-proxy?
kubelet - агент на нодах, запускает и контролирует контейнеры
kube-proxy - обеспечивает сетевую связность между сервисами
Как создать кластер Kubernetes?

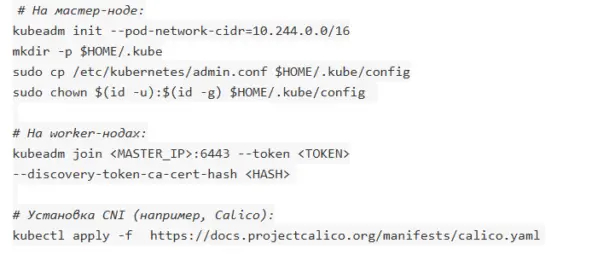

Как подключить volume к Pod'у?
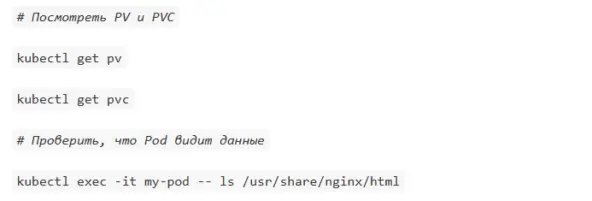
Volume (том) в Kubernetes позволяет сохранять данные между перезапусками Pod'ов. Есть несколько типов томов, но для постоянного хранения данных используются PersistentVolume (PV) и PersistentVolumeClaim (PVC).
PersistentVolume — это ресурс в кластере, представляющий физическое хранилище (например, диск в облаке или NFS-шару). PV создаётся администратором кластера и существует независимо от Pod'ов.
PersistentVolumeClaim — запрос Pod'а на выделение PV. PVC связывается с подходящим PV (или динамически создаёт его, если настроен StorageClass). PVC монтируется в Pod как volume. Если не хочется создавать PV вручную, можно использовать StorageClass для автоматического создания томов.
Чем отличается Horizontal Pod Autoscaler от Vertical Pod Autoscaler?
HPA масштабирует количество Pod'ов на основе метрик нагрузки (увеличивает или уменьшает число реплик (replicas) Deployment'а в зависимости от, например, CPU или памяти, т.е., нагрузка выросла — добавили ещё Pod'ов).
VPA изменяет ресурсы (CPU, память) у контейнеров внутри Pod'а
Для Middle DevOps
Как настроить Ingress для доступа к сервису?
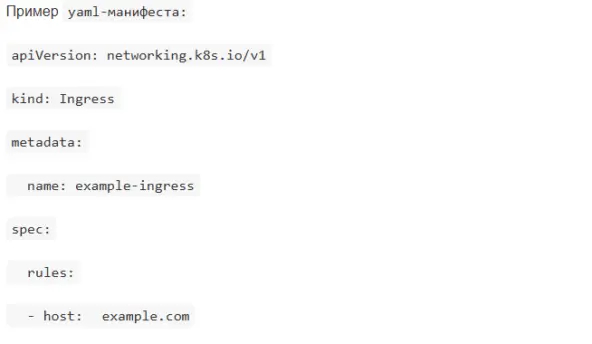
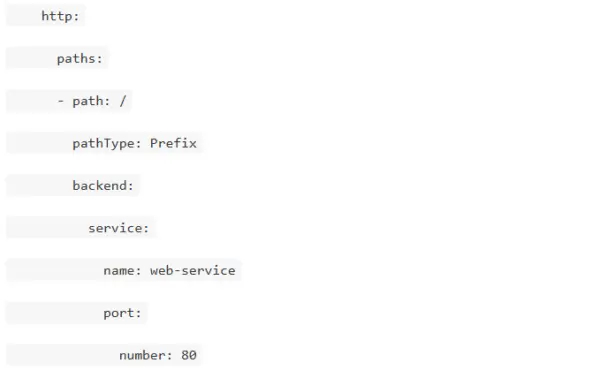
Как сделать Horizontal Pod Autoscaler (HPA)?
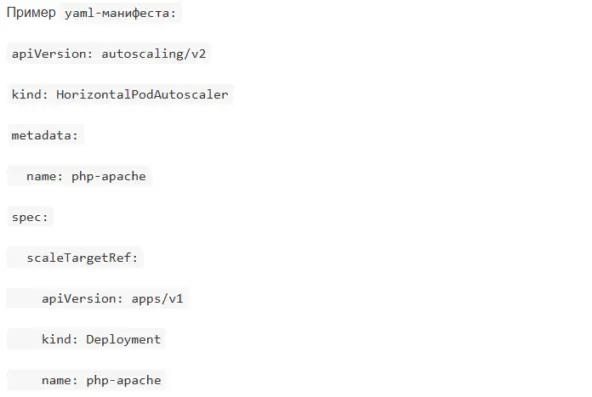

Как управлять ресурсами (requests/limits)?

Как настроить PersistentVolume для stateful-приложения?

Как диагностировать проблему с CrashLoopBackOff?
Посмотреть логи пода
Проверить readiness/liveness пробы
Убедиться, что контейнеру хватает ресурсов
Проверить монтирование томов
Изучить события кластера:kubectl describe pod <pod-name>kubectl get events
Для Senior DevOps
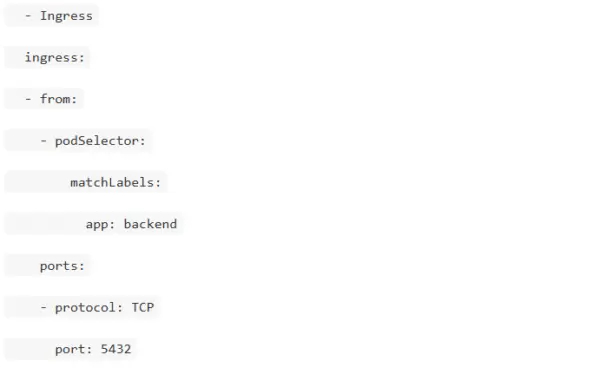
Как настроить NetworkPolicy для изоляции подов?

Как работает etcd и что делать при его проблемах?
Распределенное key-value хранилище - "мозг" Kubernetes. Проблемы и решения:
Недостаток места: регулярная дефрагментация
Высокая задержка: оптимизация сети
Потеря кворума: восстановление из бэкапа
Как настроить мониторинг (Prometheus + Grafana)?
Установка Prometheus Operator
Настройка ServiceMonitor для сбора метрик
Создание Grafana дашбордов
Настройка алертов через Alertmanager
Как организовать multi-cluster управление?
Варианты:
Kubefed (Federation v2)
Cluster API
Коммерческие решения (GKE Anthos, EKS Anywhere)
Основные задачи: синхронизация ресурсов, единая аутентификация, централизованное логирование.
Как оптимизировать costs в облачном k8s (автоскейлинг нод)?
Использование spot-инстансов
Автомасштабирование нод (Cluster Autoscaler)
Вертикальное масштабирование подов (VPA)
Планирование подов на дешевые ноды (node affinity/taints)
Использование serverless-решений (AWS Fargate, GCP Cloud Run)
Заключение: Kubernetes — мощный инструмент, но не панацея
Kubernetes действительно стал стандартом для оркестрации контейнеров в современных облачных и гибридных средах. Он решает ключевые задачи: масштабируемость, отказоустойчивость и автоматизацию деплоя. Однако его внедрение требует взвешенного подхода — не каждый проект нуждается в такой сложности.
Главный совет:
Если у вас микросервисы, высокая нагрузка или требовательная инфраструктура — Kubernetes может стать вашим решением.
Если проект небольшой или монолитный — начните с простых решений (Docker Compose, managed-сервисов) и масштабируйтесь постепенно.
Попробуйте Kubernetes в действии:
Разверните локальный кластер через minikube или kind.
Поэкспериментируйте с Helm-чартами и автоскейлингом.
Изучите managed-решения (GKE/EKS/AKS), чтобы оценить их преимущества.
Показать полностью
15
Deckhouse Conf 2025: как прошла первая техническая конференция от команды Deckhouse
Масштабная технологическая конференция объединила свыше 500 ведущих специалистов в области DevOps, Kubernetes и платформенной разработки

Deckhouse Conf 2025 - первая техническая конференция команды разработчиков Deckhouse
Компания «Флант» провела Deckhouse Conf 2025 — первую техническую конференцию, организованную командой разработчиков Deckhouse, которая состоялась в Центре событий РБК. Событие объединило более 500 ведущих специалистов в области DevOps, Kubernetes и платформенной разработки.
Deckhouse Conf 2025 стала площадкой для обмена опытом и обсуждения актуальных вопросов Cloud Native-разработки. Программа конференции включала доклады, посвященные практическим аспектам работы с Kubernetes, информационной безопасности, мониторингу, DevOps и SRE. Участники узнали о последних обновлениях продуктов Deckhouse, планах развития Deckhouse Kubernetes Platform и получили ценные рекомендации по оптимизации инфраструктуры и повышению эффективности процессов разработки.

Александр Титов, генеральный директор компании «Флант»
«2024 год для Deckhouse Kubernetes Platform стал периодом стремительного развития — платформа показала рост выручки на 170%, а к началу 2025 года количество управляемых кластеров превысило 1000. Согласно исследованию TAdviser, объём российского рынка коммерческих платформ контейнеризации в 2023 году составил 931 млн рублей с учётом выручки от лицензий и поддержки OnPremise-решений. В этом сегменте платформа Deckhouse Kubernetes Platform от компании «Флант» уверенно занимает лидирующие позиции с долей рынка 31%», — рассказал Александр Титов, генеральный директор компании «Флант».
Технологическая дорожная карта Deckhouse Kubernetes Platform в 2024 году была направлена на расширение поддерживаемых вычислительных сред и наращивание функциональности. Главным требованием при добавлении новых возможностей и внесении изменений являлось сохранение достигнутой производительности и объема потребляемых ресурсов. На текущий момент крупнейшая промышленная инсталляция DKP насчитывает более 450 узлов и свыше 20000 подов.

Давид Мэгтон, технический директор, сооснователь компании «Флант»
«Kubernetes перестал быть просто инструментом — теперь это новый стандарт для управления инфраструктурой, — отметил Давид Мэгтон, технический директор, сооснователь компании «Флант». — Но с ростом технических возможностей повышается и сложность управления ими. Наша миссия состоит в том, чтобы разорвать эту связь и обеспечить простоту разработки. Поэтому основой развития DKP является подход SDx (Software Defined Everything), поверх которого строится “правильный” API».
Давид Мэгтон выделил пять главных принципов, на основе которых происходит развитие API DKP. Первый – декларативный подход: пользователь задает правила, по которым система выполняет необходимые операции с использованием собственных механизмов. Второй – одна точка изменения того или иного параметра в API, обеспечивающая простоту использования. Третий – единообразие: применение единых подходов и терминов для всех инструментов управления в экосистеме. Четвертый – защита от неправильного использования: автоматическое ограничение нерабочих комбинаций параметров конфигураций. Пятый – обратная связь на любое действие пользователя.

В DKP реализованы такие подходы, как исправление возникающих ошибок уже на ранних этапах разработки; фокус на создании долгосрочных решений; готовность к постоянным изменениям в создаваемом решении. Они являются важными факторами, гарантирующими возможность применения платформы для построения цифровых продуктов и Cloud Native систем.
«Мы помогаем бизнесу управлять приложениями и ресурсами. Наша платформа знает, что нужно приложению, и может динамически подстраиваться под нагрузку — давать больше или меньше ресурсов: процессора, памяти и так далее. В этом преимущество DKP: платформу можно использовать в окружении с разными и меняющимися нагрузками. Это не коробка, в которой ничего нельзя поменять — это открытая платформа, которая развивается в такт с потребностями заказчика, обеспечивая непрерывные обновления и интеграцию с другими системами, чтобы новые возможности появлялись без долгого ожидания и приносили максимум пользы. Вся индустрия движется к этому подходу, и мы задаем тренд», — подчеркнул Александр Титов.
Таким образом, развитие DKP имеет свои особенности, но идет в соответствии с трендами эволюции всей экосистемы Kubernetes. Сегодня решение успешно применяется во всех ключевых секторах экономики: финансовые организации, государственный сектор, промышленные предприятия, ритейл и e-come выбирают Deckhouse Kubernetes Platform для своих цифровых инфраструктур. Платформа одинаково эффективно работает в любых средах — от bare-metal серверов до сложных гибридных архитектур, подтверждая свою репутацию наиболее универсального и надёжного решения для контейнеризации на российском рынке.
Фото Deckhouse conf доступно по ссылке
Показать полностью
4