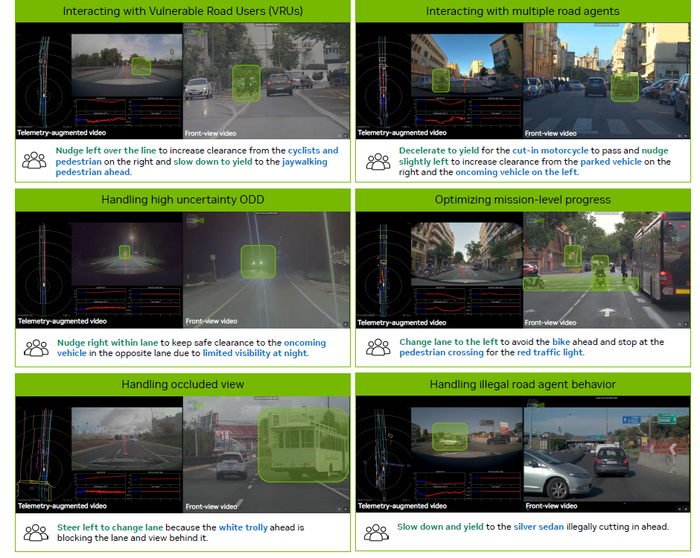
Выложена авторегрессионная модель для генерации изображений, насыщенных знаниями, с высокой точностью GLM-Image (https://huggingface.co/zai-org/GLM-Image).
Она первая открытая промышленная модель, сочетающая авторегрессионный трансформер (9B параметров, на основе GLM-4) для понимания семантики и диффузионный декодер (7B параметров, DiT) для детализации.
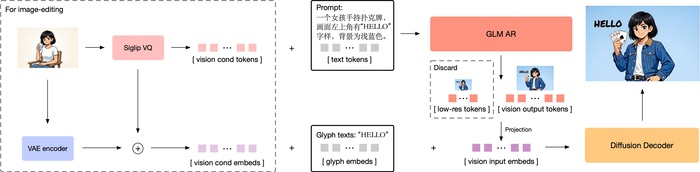
Использование гибридной архитектуры обеспечивает ей преимущество в сложных задачах, давая лучшее следование инструкциям, рендеринг текста и работу со знаниями, а ещё высокую детализацию. Кроме того, есть поддержка множества задач, таких как Text-to-Image, редактирование, стилизация, сохранение идентичности.
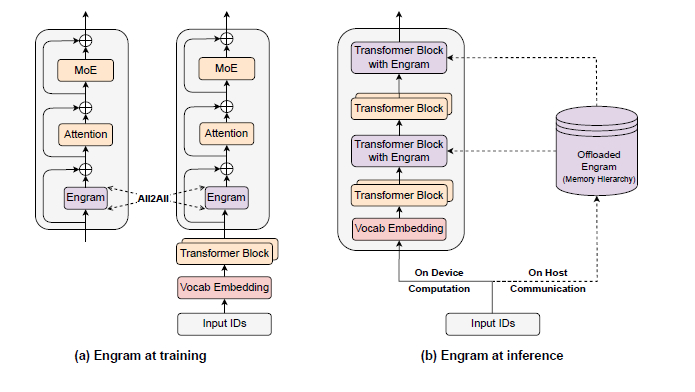
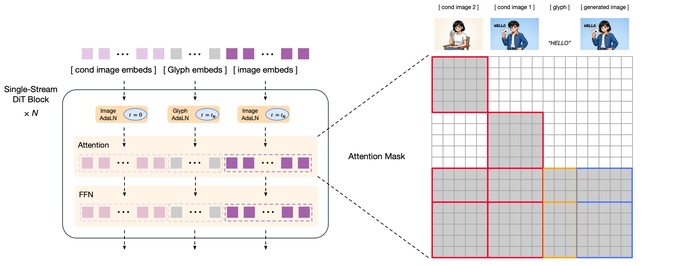
При токенизации в ней используется semantic-VQ (XOmni) для лучшей семантической связи токенов. Обучение AR-части включало многоэтапное обучение на разных разрешениях с прогрессивной стратегией генерации. Диффузионный декодер выполнял условную генерацию на основе семантических токенов, где для работы с текстом и редактирования добавлены glyph-эмбеддинги и блок-каузальное внимание. Также во время post-training проводили раздельную оптимизацию AR-модуля (семантика, эстетика) и декодера (детали, текст) с помощью GRPO.
В результате модель лидирует по рендерингу текста (CVTG-2k, LongText-Bench) и конкурентоспособна в общих задачах (OneIG, DPG Bench, TIFF Bench).