
0 просмотренных постов скрыто


Ответ на пост «Говорилка Qwen3-TTS с поддержкой русского языка. Бесплатная нейросеть озвучит что угодно вашим голосом + портативная версия»2
Оставьте образец голоса, пожалуйста!
Звонков и голосовух родственникам и знакомым точно не будет!

Говорилка Qwen3-TTS с поддержкой русского языка. Бесплатная нейросеть озвучит что угодно вашим голосом + портативная версия2
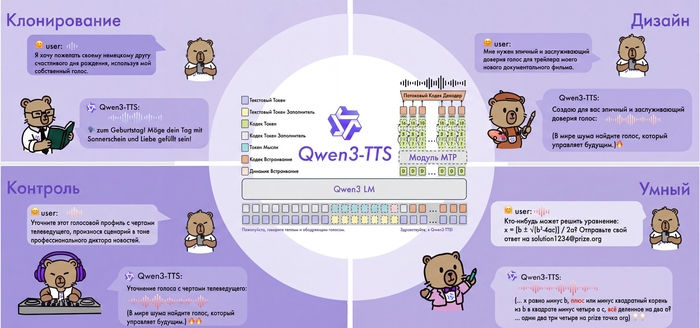
Всем привет! Команда Qwen от Alibaba выложила в открытый доступ Qwen3-TTS — нейросетевую модель для синтеза речи с клонированием голоса. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А еще я сам собрал портативную версию Qwen3-TTS под win11 и успел её как следует протестировать.
Главная особенность системы в том, что она умеет не только озвучивать текст готовыми голосами, но и клонировать любой голос по короткому образцу, а ещё создавать новые голоса по текстовому описанию.
И всё это с нативной поддержкой русского языка.
Как это работает
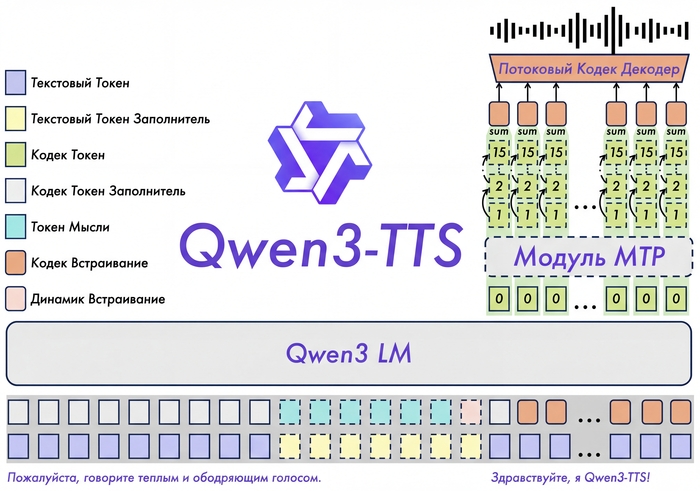
В основе Qwen3-TTS лежит End-to-End архитектура с дискретным многоканальным токенизатором речи (12.5 Гц, 16 слоёв). В отличие от традиционных систем, которые работают по цепочке "текст → фонемы → звук" и теряют информацию на каждом этапе, здесь всё обрабатывается одним махом.
Такой подход полностью исключает эффект "роботизированности" и каскадные ошибки генерации. Модель сохраняет интонации, эмоции и особенности тембра.
Работает очень быстро даже на старшей модели 1.7B.
Поддерживаемые языки
Qwen3-TTS работает с 10 языками:
Китайский (включая пекинский и сычуаньский диалекты)
Английский
Японский
Корейский
Немецкий
Французский
Русский
Португальский
Испанский
Итальянский
Возможности
Синтез с готовыми голосами (CustomVoice)
9 встроенных голосов разных типов — молодые и зрелые, мужские и женские. Можно управлять эмоциями и стилем речи через текстовые инструкции.
Создание голоса по описанию (VoiceDesign)
Описываете словами, какой голос нужен — модель его генерирует. Например: "молодой женский голос, игривый, с высоким тоном". Лучше работает если писать промпты на голос на английском.
Клонирование голоса (Voice Clone)
Загружаете аудио от 3 секунд — получаете синтез этим голосом. По бенчмаркам качество клонирования превосходит ElevenLabs и MiniMax по показателям сходства спикеров. Оно и правда веского качества, уровень VibeVoice, но гораздо легче по ресурсам.
Multi-Speaker режим
Создание диалогов и подкастов с несколькими спикерами одновременно (до 4 голосов).
Можно эмулировать разговор между друзьями, актерами, персонажами из игры, все теперь ограничивается только вашей фантазией.
Кому пригодится
Создателям контента — озвучка роликов, подкастов, стримов.
Разработчикам игр — озвучка персонажей без найма актёров, особенно актуально для инди.
Аудиокнигам — разные голоса для персонажей.
Автоматизации — голосовые уведомления, IVR-системы, ассистенты.
Как попробовать
Онлайн-демо
Тут в демо меньше возможностей и нет локализации, но тоже отлично работает.
Hugging Face Demo — https://huggingface.co/spaces/Qwen/Qwen3-TTS
Официальный GitHub
Можно попробовать установить самостоятельность с гитхаб, но это потребует опыта и навыков.
API
Официальное API от Alibaba для production-интеграции.
Портативная версия
Я с каналом Нейро-Софт подготовил улучшенную портативную сборку Qwen3-TTS Portable PRO, видео выше как раз из неё и записаны. А еще там:
Русифицированный интерфейс
Установка в один клик (install.bat)
50+ готовых голосов в комплекте
700+ дополнительных голосов для скачивания из интерфейса
Multi-Speaker режим до 4 спикеров
Поддержка NVIDIA GPU и CPU
Системные требования
NVIDIA GPU с 8+ ГБ видеопамяти (или CPU, но медленнее)
Windows 10/11 64-bit
16 ГБ оперативной памяти
20 ГБ свободного места на диске
Текущие ограничения
Ударения иногда расставляются неправильно
С длинными текстами могут быть проблемы
Инструкции для VoiceDesign лучше писать на английском
Распакуйте в корень диска (путь без кириллицы), запустите install.bat. Модели скачаются при первом запуске. А если будут сложности в установкой в посте в канале найдете версию с уже установленным env (окружением).
Я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Ну и на канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял и удачных генераций!
Показать полностью
2
7

Вышла новая модель для синтеза речи Qwen3-TTS
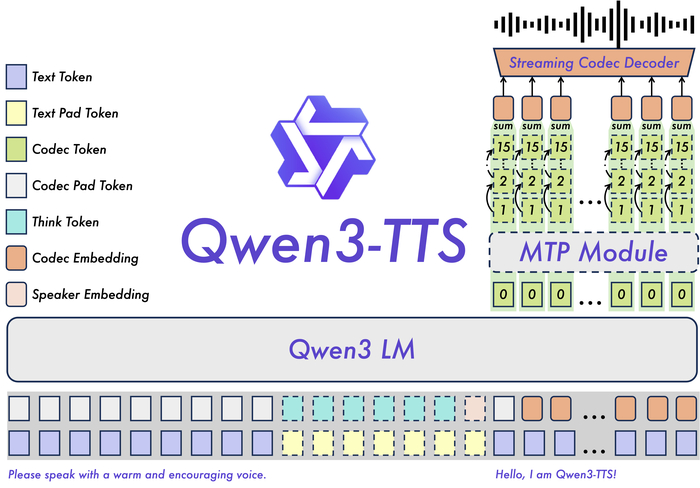
Нам теперь открыта серия мощных моделей генерации речи Qwen3-TTS (https://huggingface.co/collections/Qwen/qwen3-tts). Она доступна в двух размерах (1.7B и 0.6B) и поддерживает 10 основных языков.
У этой модели есть возможность клонирования голоса по 3-секундному образцу, а также создание нового голоса по текстовому описанию. Ещё она поддерживает детальное управление характеристиками речи (тембр, эмоции, интонация) через инструкции. При всём этом у неё сверхнизкая задержка при потоковой генерации.


Показать полностью
2
Вышла новая модель для синтеза речи GLM-TTS
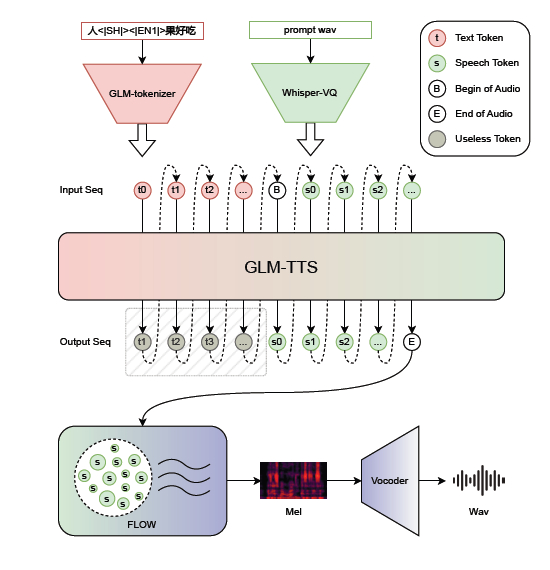
Выложена производственная система синтеза речи (TTS), ориентированная на эффективность, управляемость и качество GLM-TTS (https://huggingface.co/zai-org/GLM-TTS).
Она имеет двухэтапную архитектуру, в которой соединена авторегрессионная модель "текст-в-токены" и диффузионная модель "токены-в-волну". В ней присутствует оптимизированный токенизатор речи на основе Whisper-VQ с ограничениями по тону (F0) и увеличенным словарём, что даёт результат в виде высокой схожести голоса (SIM=76.1) и низкой частоты ошибок по символам (CER=1.03%).
Её обучение было с подкреплением (RL) по методу GRPO с несколькими reward-функциями (произношение, схожесть, эмоции, смех), благодаря чему улучшалась выразительность и стабильность обучения. Кастомизация голоса через тонкую настройку LoRA (только ~15% параметров) является низкозатратной, и для этого требуется ~1 час аудио целевого голоса.
А точный контроль произношения через гибридный ввод "текст + фонемы" решает проблему омофонов и редких слов, особенно для китайского языка. Улучшенный вокодер Vocos2D с 2D-свертками может лучше моделировать частотные поддиапазоны, повышая качество звука.
В итоге по эффективности модель достигает SOTA (state-of-the-art) результатов на открытых бенчмарках, обучаясь всего на ~100k часов данных (значительно меньше аналогов).
Показать полностью
1


Генератор Русской Озвучки для Игр
Процесс запущен.
Создал инструмент для автоматической локализации аудио в играх. Изначально делал для себя — для перевода небольших старых проектов.
Качество, конечно, до профессиональной озвучки не дотягивает: пока использую один голос и накладываю его на оригинальное аудио. Зато эмоции персонажей сохраняются, получается как в фильмах 90-х — та самая одноголосая озвучка на кассете, немного ностальгии.
Пару обработанных файлов тут (тут аудио не выкладываются)
🔹 Фильтрует смех и звуки — не озвучивает "ха-ха", "вуху", "смеется", "wow" и подобное. Смех остается оригинальным.
🔹 Исправляет ударения — ставит правильные ударения в русском тексте, особенно в игровых терминах (атака́, защи́та, урове́нь).
🔹 Работает в один клик — веб-интерфейс в браузере, отслеживание прогресса, статистика.
Технологии:
Whisper AI — распознавание английской речи
Silero TTS — синтез русской речи
LibreTranslate — перевод
Python — основа всего
Недостатки:
Доставать файлы из игры и запаковывать обратно всё так же сложно
Пропуски в фильтрации смеха еще есть (будем исправлять)
Скоро покажу полную демонстрацию. А пока — пример исходного и обработанного файла в приложении тут.
Показать полностью
1
My Robot – будущее геймдева на пороге
Я листал ленту DTF и обнаружил в комментариях рекомендацию попробовать игру My Robot.

Сказано – сделано. Я скачал игру, архив весил меньше 800 мегабайт. Запустил, побегал немного, и через некоторое время игра предложила настроить AI-функции. Модели STT, LLM можно было выбрать, а вот TTS был доступен только подписчикам Patreon.
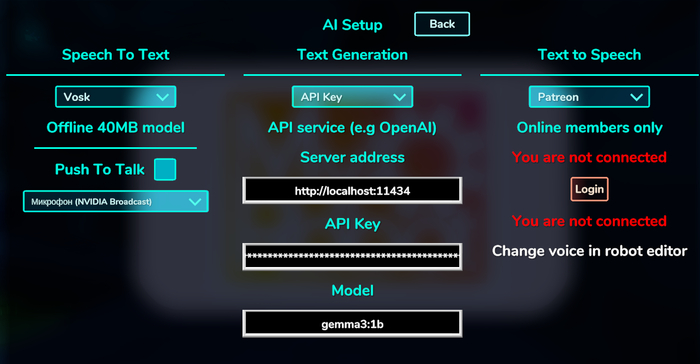
Причём возможности тонкой настройки порадовали: можно использовать как локальные большие языковые модели (koboldcpp backend), так и облачные через API.
Я сначала выбрал модель YandexGPT на 8 миллиардов параметров и полученный результат меня повеселил.
Затем мне хотелось подключить через ollama модель gpt-oss-120b, но оказалось, что через API можно подключать только локальные модели (либо это ограничения бесплатного тарифа), поэтому остановился на gemma3-1b. Особенно было забавно, когда прямо в диалогах появлялись теги <think>.
Сторонние STT-модели выбрать к сожалению, нельзя, доступны только англоязычные варианты моделей vosk и whisper. А жаль, голосом общаться намного удобнее.
Игра находится на ранней стадии разработки, поэтому багов здесь предостаточно. Я отобрал самые весёлые моменты.
В целом игра сырая, но потенциал геймплейных механик радует. Энтузиасты создают любительские моды популярных игр, которые дают им вторую жизнь. Взять ту же модификацию для Morrowind.

Уже сейчас можно создавать экспериментальные игры уровня Facade.

И если тогда это казалось подвигом и грамотным геймдизайном, то сегодняшние технологии открывают возможности для более грандиозных игровых миров.
Поэтому я с оптимизмом смотрю на подобные экспериментальные проекты. Когда-нибудь мы увидим шедевры, которые станут признанной классикой. А дорожку им протопчут энтузиасты, подобные разработчику My Robot.
Показать полностью
5
2

Программа или нейронка для озвучки текста: пытаюсь понять, что лучше
Сейчас только ленивый не ведет блог и не создает собственный контент. Однако рисовать - сложно, писать-читать - скучно. Поэтому талантливые и креативные, вроде меня, выбирают видосики. Готовясь покорять просторы ТикТока и ВК Видео, я озаботился созданием голосовых дорожек. Писать звук с телефона параллельно со съемкой видео удается не всегда. Птицы, собаки, машины, строительная техника, ветер все заглушают. И этот вариант не подходит, когда делаете смешные комментарии к другим роликам. В поисках подходящего инструмента я опробовал несколько программ для озвучки текста. Заодно потестировал модные нейросети.
Стартер пак: оборудование
Если соберетесь заниматься озвучкой, понадобится не только софт. Приложение не сможет магическим образом перенести ваш голос в mp3 файл. Чтобы волшебство заработало, нужно подключить микрофон, активировать запись и зачитать подготовленный текст.
Микрофон, встроенный в ноут, вебку или смартфон, не подойдет. За очень редкими исключениями у него плохое звучание. Кроме того, такие микрофоны всенаправленные. Они не сфокусированы на узкое пространство, а улавливают все вокруг. Из-за этого на запись попадают посторонний шум и лишнее эхо (если находитесь в просторной комнате). Для созвонов с коллегами, друзьями и родственниками это не критично, а интернет-аудиторию отпугивает.
Все сказанное справедливо и для гарнитур с наушниками-вкладышами. Бонусом - если не придерживать их микрофон, он будет тереться об одежду и тело, а на запись попадет мерзкий шуршащий звук
С более продвинутыми моделями, где микрофон крепится к подвижному держателю, все сложно. Мне не удалось найти критерии, которые позволили бы распознать хороший экземпляр. Характеристики интересные, цена высокая, а на деле звучание как у гарнитуры в комплекте к древнему телефону.
На мой взгляд, оптимальный вариант - USB-микрофон. Приемлемое качество обеспечивают даже относительно дешевые модели по цене 2,5-4 тыс. рублей. В комплекте часто идут стойка, ветрозащита (поролоновая насадка) и поп-фильтр. Пока изучал отзывы и обзоры, к своему удивлению выяснил, что такими устройствами не брезгуют и профессиональные дикторы. Не звезды первой величины, но все же.
Если не хотите экономить с USB-микрофонами и искать компромиссы по качеству, то готовьтесь покупать:
Конденсаторный микрофон — может похвастаться отличной чувствительностью и охватом частот в широком диапазоне.
Аудиоинтерфейс — профессиональная звуковая карта, имеет качественные входы и продуманные системы шумоподавления.
Микшер — главным образом нужен как источник фантомного питания, если такового не окажется в аудиоинтерфейсе. Без отдельного питания конденсаторные микрофоны не работают.
Также не обойтись без подходящего места, где не будет слышно уличного шума, соседа с перфоратором и вечноголодной кошки.Если не хотите ничего покупать, не можете укрыться от шумной суеты вокруг, сомневаетесь насчет собственной дикции, есть альтернативный вариант. С него и начну разбор программ для создания озвучки.
Начал с простого: онлайн TTS-сервисы
TTS - сокращение от “Text-to-Speech”. Означает преобразование текста в устную речь. Вы печатаете текстовые сообщения - алгоритм зачитывает их.
Синтезаторы речи существуют давно. Долгое время их звучание было крайне своеобразным. Для игрушек, прикольных эффектов для музыки и фильмов, чтения вслух объявлений и надписей для слепых и слабовидящих подходило, для более глобального использования - нет.
Машинное обучение изменило ситуацию. Хорошая нейросеть весьма точно имитирует человеческую речь и способна делать это в реальном времени. Если вам звонят с неизвестного номера, собеседник странновато себя ведет и пытается что-то впарить, то это наверняка искусственный интеллект.
Авторы видосов давно додумались “нанимать” нейронку. Они используют программы для озвучки текста онлайн, которые доступны из браузера на любом устройстве. Этот софт очень похож друг на друга. Пользователь отправляет текстовый файл или вставляет сообщение из буфера обмена. Генератор голоса сразу зачитывает их или выдает аудиодорожку. Какие-то сайты бесплатные. У других - тарификация по символам. Некоторое количество знаков предоставляется в качестве бонуса. Остальное - приобретается пакетами или подпиской.
Вот популярные варианты, которые я нашел:
Google Text-to-Speech. Для коммерческого использования и доступа ко всем функциям нужна подписка, которую из России не оформить. На сайте есть бесплатный генератор, который зачитывает короткие фразы. Пользователям доступны выбор языка, настройки скорости и высоты тона. Для русского предусмотрено 8 голосовых движков. Женские звучат довольно естественно, а в мужских заметны металлические призвуки.
Яндекс SpeechKit. Брат-близнец сервиса от Google. Подписку оформить можно, но если вы не крупная компания, это вам вряд ли нужно. Тестовая версия доступна простым смертным. Они могут отправлять сообщения до 500 знаков, выбирать язык и регулировать скорость. Русскоговорящих движков 17. У них есть настройки интонации, например, нейтральная, шепот, строгая, радостная, но список доступных вариантов каждый раз разный. Можно вручную обозначать ударения (нужно поставить “+” перед гласной) и паузы (за это отвечает “-”). ИИ зачитает сообщение или сгенерирует ogg-файл с озвучкой, а чтобы жизнь медом не казалась, добавит в конце “текст озвучен Яндекс SpeechKit” (ну не вотермарк же лепить на аудио?).
Реалистичную речь выдают несколько женских пресетов. Разница между интонациями, на мой взгляд, едва заметна. Остальные движки явно говорят голосом робота. Если повозиться с настройками сервиса, можно немного сгладить артефакты. Или получится убрать их в стороннем приложении для озвучки видео на ПК.
ElevenLabs. Позволяет пользователям бесплатно генерировать 10 минут аудио. За остальное придется платить - от $5 каждый месяц. Есть функция клонирования: загружаете готовые аудиофайлы в качестве образцов, ИИ их анализирует и начинает разговаривать с тем же тембром. Интерфейс на английском языке, но разобраться в иностранных словах несложно.
Можно вручную обозначать эмоции (прописываются по-английски в квадратных скобках) и создавать диалоги - “персонажи” по очереди будут зачитывать свои реплики. Нейронка воспроизводит все на сайте или выдает mp3-файл. Если б не проблемы с доступом и оплатой из России, я бы назвал сервис идеальным решением для чтения электронных книг. Вполне реально добиться естественного звучания. Для видеококонтента маловато различных акцентов.
TTSMP3. Браузерное приложение для озвучки персонажей. Для обычной технологии синтезасервис предлагает по одному мужскому и женскому пресету с лимитом 3 тыс. символов. Настройки высоты и скорости произношения указываются специальными командами прямо в тексте. У нейронки 9 голосов, но по-русски говорит с акцентом. Ограничения - 1 тыс. знаков в день. Дополнительно предлагается платная версия. За $5 на сутки можно получить 250 тыс. символов или за $10 - столько же, но на месяц. Результат сразу зачитывается или сохраняется в mp3. Общее качество - посредственное. Явный плюс только в бесплатной пробной версии, для которой не нужно регистрироваться.
Подводя итог: потенциал конвертеров текста огромен. В будущем технология наверняка потеснит актеров, дикторов и возможно даже вокалистов. Сейчас - подходит только для личного пользования (генерации аудиокниг, например), озвучивания видео с рекламой, низкобюджетных презентаций и намеренной стилизации речи ради комического эффекта. Для серьезных задач ее задействовать не стоит. Зритель распознает нейронку, а дальше - выключит ролик или будет воспринимать его как мемное видео.
Продолжил сложным: программы для домашней и не только записи звука
После распознавания текстов ИИ вернемся к тому, с чего начали, т.е. к записи через микрофон. В этом случае понадобится кое-какое оборудование (о нем см. выше), более-менее приятный голос, умение говорить им внятно, последовательно, без слов-паразитов и, крайне желательно, без матюков. А еще потребуется специальное приложение. Я в тонкости студийной работы не посвящен, поэтому искал что попроще - опробовал несколько софтин из вот этой подборки программ для звукозаписи.
Audacity
Интуитивно понятный интерфейс: спорно
Пробный период: навсегда
Постобработка: полно
Бесплатный аудиоредактор, выпущенный для разных платформ. Поддерживает работу с несколькими дорожками, что позволяет использовать как программу для озвучки видео разными голосами. Можно закинуть каждого персонажа на свой трек и обрабатывать индивидуально. Навигация по проекту и нарезка реализованы понятно. Чтобы нормально пользоваться другими инструментами, нужны специальные знания. Расставлять параметры наугад не имеет смысла.
Оценка: 5 впечатлений из 5, или 2 чайника из 5 звукоинженеров
Аудиомастер
Интуитивно понятный интерфейс: да
Пробный период: 5 дней
Постобработка: в наличии
Простой редактор, в котором нет ничего лишнего. У него удобный интерфейс, жмем красную кнопку - включаем запись. Ею же - останавливаем. Легко вырезаем ненужное. Эффекты перечислены слева. Знания элементарной теории не помешают, но готовые шаблоны выручают неофитов. Сохраняет в несколько форматов аудио. В их числе все основные - ogg, wav, mp3.
Оценка: 5 нубов из 5
Wavepad
Интуитивно понятный интерфейс: нет
Пробный период: для некоммерческих задач используйте сколько хотите
Постобработка: много и еще больше
Выглядит крайне наворочено. Включать запись, нарезать контент несложно. Со всем остальным нубам лучше не соваться. При использовании в качестве приложения для озвучки фильмов пригодится аудиобиблиотека. В ней огромное количество файлов. Есть звуки выстрелов, шум толпы и леса, телефонные гудки и много другого.
Оценка: 5 звукорежиссеров из 5 студий, или 1 новичок из 5 профессионалов
Ocenaudio
Интуитивно понятный интерфейс: да, если знаете, что делать
Пробный период: навсегда
Постобработка: имеется
Редактор-противоречие. Выглядит простенько и приятненько, но когда начинаешь открывать эффекты, появляются вопросы: что тут крутить-вертеть? При экспорте недоумение усиливается. К форматам wav, flac, ogg претензий нет. А mp4 сбивает с толку. Видео приложение не отображает. Если импортировать ролик, просто извлечет аудиодорожку. При сохранении в тот самый mp4 получаем m4a. Формально - все по-честному (m4a - часть стандарта mp4), но людей путает.
Оценка: 3 начинающих автора из 5 ветеранов индустрии
Wavosaur
Интуитивно понятный интерфейс: нет
Пробный период: навсегда
Постобработка: почти нет
Не вызывает ничего, кроме удивления. Скажу сразу: как программу для записи озвучки не рекомендую. Она кажется крайне устаревшей. Когда активировал непосредственно запись, решил, что редактор заглючили или повис. На экране, на первый взгляд, не происходит ничего. Только если присмотреться, можно заметить, что таймер меняется и в заголовке отображается, сколько времени прошло с начала процесса. Сохраняет только в wav или mp3, но обычного этого достаточно.
Оценка: 1 стегозавр из 5 диплодоков
Человек vs нейронка: оцениваю результаты
Я опробовал все нейронки и редакторы, о которых написал выше. Когда эмоции поутихли, могу сказать, что у каждого из вариантов есть уникальные достоинства и фундаментальные недостатки. Для наглядности решил сравнить программы для озвучки на ПК с веб-сервисами с ИИ по нескольким критериям.
Критерий - Победитель
Затраченное время - Нейросеть
Интонационная ритмика - Человек
Способность передавать эмоции - Человек
Отсутствие “металлического” оттенка - Человек
Склонение числительных - Человек
Возможность дублей. - Человек
Персонализация - Человек
Авторский стиль - Человек
Имидж проекта - Человек
ИИ - чемпион скорости. Человек последовательно произносит все слова, вставляет вскрики-вздохи и другие эмоции. А еще устает, запинается, делает оговорки, бывает в нерабочем настроении, может заболеть ангиной или насморком, всю ночь горланить в караоке и сорвать голос на много дней. И не забываем, что у людей скорость чтения индивидуальная. У инструментов преобразования с нейросетью на создание аудиофайлов уходит несколько секунд или минут, когда информации много.
Если не брать в расчет случаи, когда у человека отвратительная дикция, специфический тембр, полное отсутствие харизмы и минимальных актерских способностей, представители нашего вида лучше справляются с речью. Мы можем обыгрывать эмоции. Если и допускаем речевые ошибки, то все равно звучим как живые люди.
У голоса ИИ, если прислушаться, если специфический призвук. Машина часто делает неестественные паузы и путается в ударениях. Причем допускает свои собственные, крайне характерные ошибки. Значит, зритель или слушатель быстро определит, кто на самом деле стоял перед микрофоном.
За исключением случаев, когда авторы явно делают нечто стебное, машинная озвучка вызывает негатив. Аудитория считает, что создатели контента ленятся и экономят на спичках, особенно если это достаточно крупная фирма.
И победителем стал: мой вывод
В обозримом будущем у “дикторов”, подобных мне, не будет никаких шансов в конкуренции с машиной. Однако контент хочется делать здесь и сейчас. Поэтому я немного потратился на USB-микрофон и вооружился редактором. Пока остановился на Аудиомастере. По мере того, как появятся знания и опыт, его может заменить что-то более продвинутое.
Нейросети хочется приспособить под приложение для озвучки книг. Останавливает монетизация сервисов. У бесплатных синтезаторов жесткие ограничения. Не имеет смысла делить романы из сотен страниц на отрывки по несколько тысяч знаков, а потом склеивать по частям. Платные подписки такие, что дешевле нанимать чтеца и водить его за собой во время прогулок.
Если знаете сервисы лучше и дешевле, буду рад совету. Также очень приветствуются гайды по обработке звука и улучшению качества записи.
Показать полностью