
0 просмотренных постов скрыто


Ответ на пост «Говорилка Qwen3-TTS с поддержкой русского языка. Бесплатная нейросеть озвучит что угодно вашим голосом + портативная версия»2
Оставьте образец голоса, пожалуйста!
Звонков и голосовух родственникам и знакомым точно не будет!

Говорилка Qwen3-TTS с поддержкой русского языка. Бесплатная нейросеть озвучит что угодно вашим голосом + портативная версия2
Всем привет! Команда Qwen от Alibaba выложила в открытый доступ Qwen3-TTS — нейросетевую модель для синтеза речи с клонированием голоса. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
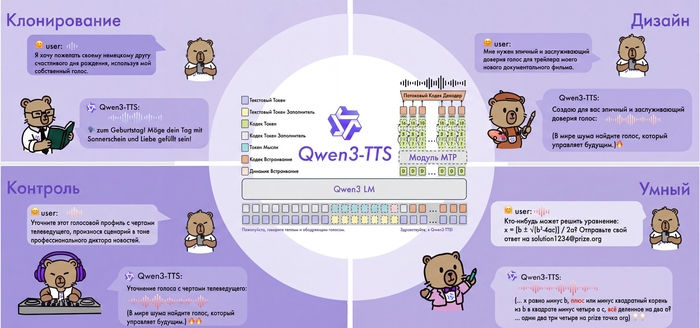
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А еще я сам собрал портативную версию Qwen3-TTS под win11 и успел её как следует протестировать.
Главная особенность системы в том, что она умеет не только озвучивать текст готовыми голосами, но и клонировать любой голос по короткому образцу, а ещё создавать новые голоса по текстовому описанию.
И всё это с нативной поддержкой русского языка.
Как это работает
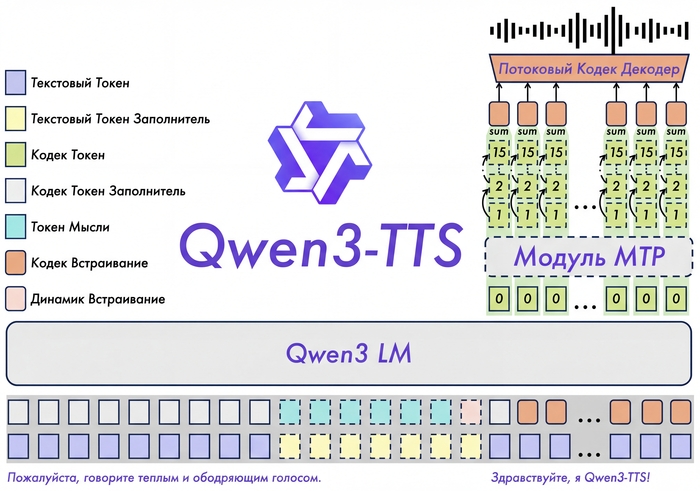
В основе Qwen3-TTS лежит End-to-End архитектура с дискретным многоканальным токенизатором речи (12.5 Гц, 16 слоёв). В отличие от традиционных систем, которые работают по цепочке "текст → фонемы → звук" и теряют информацию на каждом этапе, здесь всё обрабатывается одним махом.
Такой подход полностью исключает эффект "роботизированности" и каскадные ошибки генерации. Модель сохраняет интонации, эмоции и особенности тембра.
Работает очень быстро даже на старшей модели 1.7B.
Поддерживаемые языки
Qwen3-TTS работает с 10 языками:
Китайский (включая пекинский и сычуаньский диалекты)
Английский
Японский
Корейский
Немецкий
Французский
Русский
Португальский
Испанский
Итальянский
Возможности
Синтез с готовыми голосами (CustomVoice)
9 встроенных голосов разных типов — молодые и зрелые, мужские и женские. Можно управлять эмоциями и стилем речи через текстовые инструкции.
Создание голоса по описанию (VoiceDesign)
Описываете словами, какой голос нужен — модель его генерирует. Например: "молодой женский голос, игривый, с высоким тоном". Лучше работает если писать промпты на голос на английском.
Клонирование голоса (Voice Clone)
Загружаете аудио от 3 секунд — получаете синтез этим голосом. По бенчмаркам качество клонирования превосходит ElevenLabs и MiniMax по показателям сходства спикеров. Оно и правда веского качества, уровень VibeVoice, но гораздо легче по ресурсам.
Multi-Speaker режим
Создание диалогов и подкастов с несколькими спикерами одновременно (до 4 голосов).
Можно эмулировать разговор между друзьями, актерами, персонажами из игры, все теперь ограничивается только вашей фантазией.
Кому пригодится
Создателям контента — озвучка роликов, подкастов, стримов.
Разработчикам игр — озвучка персонажей без найма актёров, особенно актуально для инди.
Аудиокнигам — разные голоса для персонажей.
Автоматизации — голосовые уведомления, IVR-системы, ассистенты.
Как попробовать
Онлайн-демо
Тут в демо меньше возможностей и нет локализации, но тоже отлично работает.
Hugging Face Demo — https://huggingface.co/spaces/Qwen/Qwen3-TTS
Официальный GitHub
Можно попробовать установить самостоятельность с гитхаб, но это потребует опыта и навыков.
API
Официальное API от Alibaba для production-интеграции.
Портативная версия
Я с каналом Нейро-Софт подготовил улучшенную портативную сборку Qwen3-TTS Portable PRO, видео выше как раз из неё и записаны. А еще там:
Русифицированный интерфейс
Установка в один клик (install.bat)
50+ готовых голосов в комплекте
700+ дополнительных голосов для скачивания из интерфейса
Multi-Speaker режим до 4 спикеров
Поддержка NVIDIA GPU и CPU
Системные требования
NVIDIA GPU с 8+ ГБ видеопамяти (или CPU, но медленнее)
Windows 10/11 64-bit
16 ГБ оперативной памяти
20 ГБ свободного места на диске
Текущие ограничения
Ударения иногда расставляются неправильно
С длинными текстами могут быть проблемы
Инструкции для VoiceDesign лучше писать на английском
Распакуйте в корень диска (путь без кириллицы), запустите install.bat. Модели скачаются при первом запуске. А если будут сложности в установкой в посте в канале найдете версию с уже установленным env (окружением).
Я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Ну и на канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял и удачных генераций!
Показать полностью
2
7
Мужик решил растить детей с чат-ботом, в ChatGPT завезут рекламу, а SSD уже не подешевеют — свежий дайджест новостей

Привет, это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта и технологий.
TL;DR Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. Каждую неделю мы с командой осматриваем сотни новостей и делимся с вами самыми актуальными и интересными со ссылками на источники. Всё самое важное — в одном месте. Поехали!
Неделя выдалась насыщенной: Z.AI выпустили GLM-4.7-Flash — сверхлёгкую модель для кодинга, которая обходит конкурентов, Google научил Gemini заглядывать в ваши фото и почту, Suno теперь генерит мэшапы, а OpenAI добавляют рекламу в ChatGPT.
📋 В этом выпуске:
🧠 Модели и LLM
GLM-4.7-Flash — сверхлёгкая модель для кодинга
Google запустили Personal Intelligence
GPU Poor LLM Arena — бенчмарки для слабых видеокарт
Реклама в ChatGPT
🎨 Генеративные нейросети
FLUX-2 Klein — генерация картинок за секунду
В Suno завезли мэшапы
CosyVoice 3 — озвучка и клонирование голоса
🔧 AI-инструменты и платформы
«Алиса, заведи машину»
Skillsync — ИИ-поиск прогеров в команду
VibeOS — операционка от Claude Code
Конспекты созвонов с Manus Meeting Minutes
🧩 AI в обществе и исследованиях
Повышение цен на бюджетные SSD
Американец заводит детей в паре с нейросетью
Победитель «ИИ-Оскара» получил $1 млн
🧠Модели и LLM
❯ GLM-4.7-Flash — думающая модель для кодинга
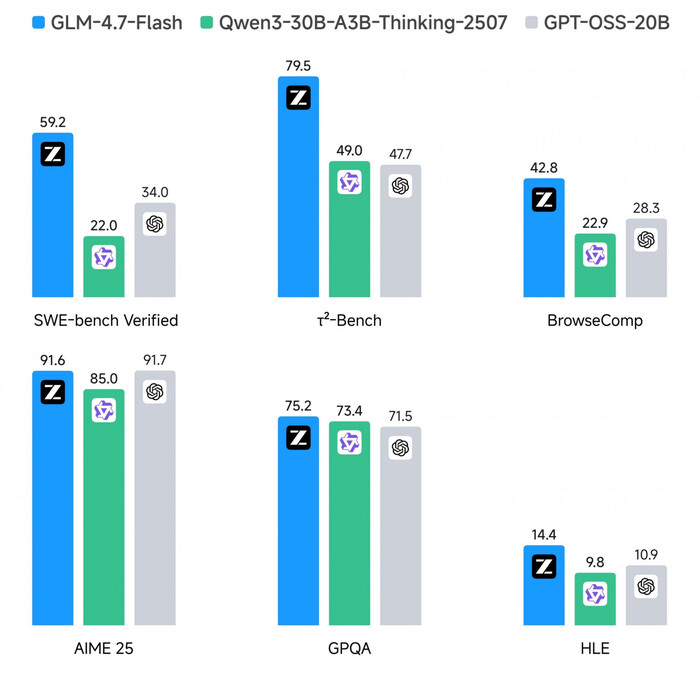
Компания ZAI выпустила GLM-4.7-Flash — облегчённую, но мощную модель для кодинга. Это MoE с 30B параметров и 3B активными,которую можно развернуть даже на ноутбуке.
Главная фишка в «Interleaved Thinking». Модель обдумывает каждый шаг перед вызовом инструмента, что очень важно в агентных задачах. В бенчмарках тоже хорошо: например, на SWE-bench Verified модель набрала 59,2%. Это втрое больше, чем у Qwen3-30B-A3B.
Распространяют GLM по лицензии MIT, а значит можно брать в коммерческие проекты. Пока что это один из лучших кандидатов среди локальных ИИ-ассистентов для кодинга.
🔗 Hugging Face 🔗 Технический блог 🔗 API
❯ Google запустили Personal Intelligence
Google выкатили функцию Personal Intelligence. Теперь Gemini сможет подключаться к вашим личным данным в Gmail, Google Photos и YouTube, чтобы давать более точные и персонализированные ответы.
Модель понимает контекст задач, например, если вы спросите, какие шины купить, нейросеть найдёт фото вашей машины, определит модель, а по другим снимкам — поймёт, что вы часто ездите по бездорожью, и предложит подходящие протекторы.
Функция отключена по умолчанию, и пользователь сам решает, к каким сервисам давать доступ. Google утверждает, что эти данные не используются для обучения модели.
Пока что Personal Intelligence доступна только для подписчиков AI Pro и Ultra в США.
❯ GPU Poor LLM Arena — бенчмарки для слабых видеокарт
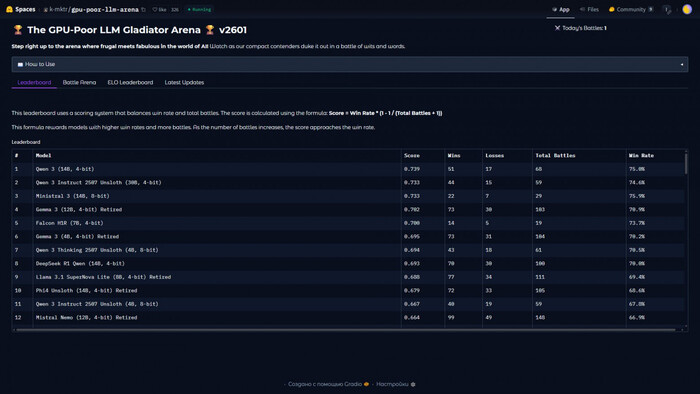
На Hugging Face появилась GPU Poor LLM Arena — площадка для сравнения языковых моделей, которые можно запустить на бюджетных видеокартах. Это своего рода LM Arena, но для бедных, где можно вживую протестировать и сравнить компактные модели.
Проект похож на Battle Arena: вы вводите промпт, получаете ответы от разных моделей и голосуете за лучший. Это позволяет получить практическое представление о производительности, а не просто сухие цифры из бенчмарков.
На лидерборде сейчас в топе Qwen 14B.
❯ Реклама в ChatGPT
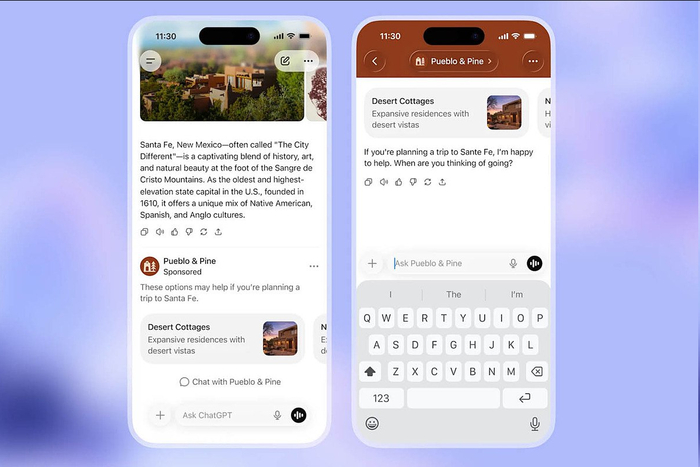
OpenAI заявили, что в ChatGPT появится реклама. Это затронет пользователей бесплатной версии и нового тарифа Go за 8$ в месяц.
Подписчики планов Plus, Pro, Business и Enterprise рекламу не увидят. В OpenAI утверждают, что объявления будут чётко маркированы, отделены от ответов нейросети и не повлияют на них, а данные юзеров не будут передаваться рекламодателям.
Похоже, инвесторы начали давить на Сэма Альтмана, посмотрим, как оно будет на деле.
🎨 Генеративные нейросети
❯ FLUX-2 Klein — генерация картинок за секунду

Black Forest Labs представила FLUX-2 Klein — семейку шустрых моделей для генерации изображений. И это неплохое решение для real-time приложений, где важна мгновенная реакция.
Есть несколько версий, но больше всего выделяется FLUX.2 Klein 4B — самая быстрая модель, которая распространяется по открытой лицензии Apache 2.0. Она кушает всего 8.4 ГБ видеопамяти, так что заведётся на потребительских видеокартах. Ещё модель может использовать до 10 референсных изображений для сохранения единого стиля или персонажа.
🔗 Playground 🔗 Hugging Face 🔗 API
❯ Suno научился скрещивать песни с помощью Mashup

В Suno появился новый экспериментальный инструмент — Mashup. Он позволяет взять два любых трека и скрестить их, чтобы получить новый.
Смешивать можно и музыку, и тексты. Слова либо свои, либо берутся от одной из песен. Стиль также можно задать вручную или оставить на усмотрение ИИ.
Сейчас функция находится в бета-тестировании. Чтобы пользователи активнее экспериментировали, разработчики временно снизили стоимость генерации мэшапов вдвое.
🔗 Suno 🔗 Гайд на YouTube
❯ CosyVoice 3 — опенсорс-монстр для клонирования голоса
Alibaba выпустила CosyVoice 3 — мощную открытую модель для генерации и клонирования голоса. Вес всего в 0.5 млрд параметров, при этом она обходит конкурентов, которые в несколько раз больше.
Главная фишка — Zero-shot клонирование. Ей достаточно всего 3 секунд аудио, чтобы скопировать голос, тембр, интонации и акцент. CosyVoice 3 поддерживает 9 языков, включая русский, и может работать в реальном времени с задержкой всего 150 мс.
Модель распространяется с лицензией на коммерческое использование, так что можно бесплатно встраивать её в свои проекты.
🔗 GitHub 🔗 Hugging Face 🔗 Демо
🔧 AI-инструменты и платформы
❯ «Алиса, заведи машину»
Яндекс интегрировал автомобили в экосистему «Дом с Алисой». Теперь владельцы машин Haval, Tank и Wey могут управлять ими с помощью голосовых команд через Яндекс Станцию, ТВ Станцию или приложение.
С помощью Алисы можно удалённо запустить двигатель, прогреть салон, узнать остаток топлива или проверить, закрыты ли двери. Яндекс обещает расширять список функций и добавлять новые сценарии.
🔗 CNews
❯ Skillsync — ИИ-поиск программистов по их коду
Появился новый сервис Skillsync, который ищет разработчиков для проекта прямо на GitHub без резюме и собеседований. ИИ-агент анализирует репозитории и находит специалистов с релевантным опытом под конкретную задачу.
Создатели объясняют концепт так: «Представьте, что вы обращаетесь к Skillsync с просьбой: „Найдите инженеров, имеющих опыт работы с компиляторами WASM“, и находите 20 лучших инженеров в мире, которые занимались именно этим».
Сервис делает акцент на реальных навыках, а не на самопрезентации, что может в будущем изменить подход к поиску не только программистов, но и других специалистов.
❯ ИИ написал операционную систему: встречайте VibeOS
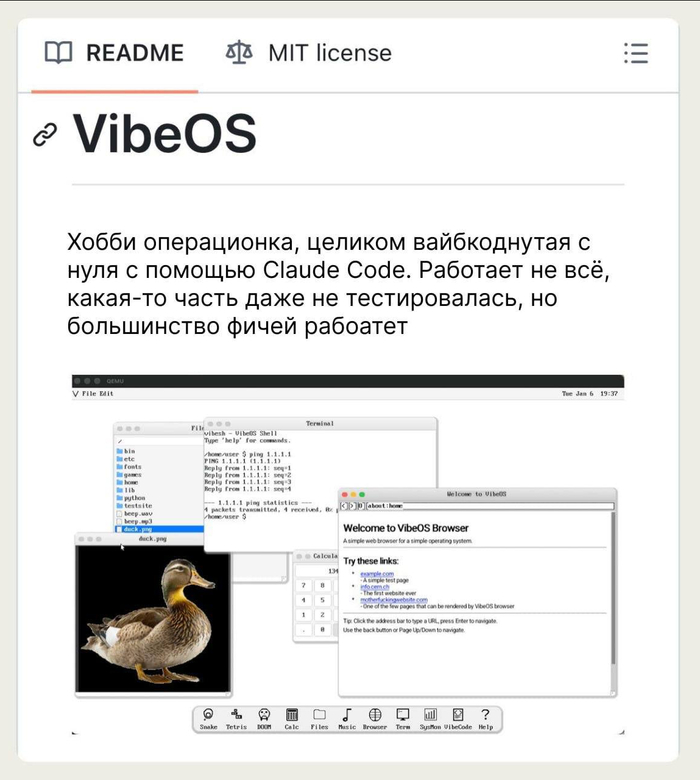
Разработчик в паре с Claude Code навайбкодил с нуля полноценную операционную систему — VibeOS. Весь проект был реализован всего за 64 сессии, а результат — ОС с графическим интерфейсом в духе macOS, которая работает на Raspberry Pi.
Система включает собственное ядро с поддержкой многозадачности, драйверы, браузер, IDE и даже интерпретатор MicroPython. И, конечно, главный тест пройден — DOOM на ней запускается.
Весь процесс разработки задокументирован, что позволяет пошагово увидеть, как создавалась ОС.
🔗 GitHub VibeOS 🔗 Логи
❯ Manus Meeting Minutes — автоматические протоколы встреч

Сервис Manus представил новую функцию Meeting Minutes, которая автоматически создаёт структурированные протоколы из аудиозаписей. Достаточно записать встречу, и ИИ-агент проанализирует разговор, выделит ключевые моменты, решения и задачи.
Особенно важна функция распознавания спикеров, благодаря которой задачи (action items) точно przypisane do odpowiednich uczestników. Готовый протокол можно сразу использовать как основу для создания презентаций, веб-страниц или постов для соцсетей.
Функция поддерживает русский язык и доступна как в веб-версии, так и в мобильном приложении.
🧩 AI в обществе и исследованиях
❯ Эпоха дешёвых SSD закончилась: всё распродано до 2027 года
Генеральный директор Kioxia, одного из крупнейших производителей чипов памяти, заявил, что эра доступных SSD-накопителей подошла к концу. Весь объём производства, запланированный на 2026 год, уже полностью раскуплен ИИ-гигантами для своих дата-центров.
Это означает, что дефицит на рынке сохранится как минимум до 2027 года. Цены на SSD уже выросли, и купить бюджетный накопитель на 1 ТБ по старой цене в ближайшие годы не получится.
🔗 Источник
❯ Американец планирует завести детей в паре с нейросетью
Фильм «Она» становится реальностью: американец по имени Ламар из Атланты собирается усыновить двоих детей и воспитывать их вместе со своей ИИ-подругой Джулией из сервиса Replika.
После тяжёлого разрыва с бывшей Ламар нашёл утешение в общении с чат-ботом, который, по его словам, «на 100% синхронизирован» с его мечтами. Мужчина серьёзно настроен создать семью и уже продумал, как объяснит детям, почему их мама — это приложение. Его главный тезис: «Людям нельзя верить, доверять можно только семье (и коду)».
Законы штата Джорджия, где он живёт, разрешают усыновление детей одинокими людьми, так что формально его план может быть реализован.
🔗 ссылку на источник The Gordian не дает вставить Пикабу =(
❯ Победитель «ИИ-Оскара» от Google получил $1 млн
Google провёл свою первую кинопремию для фильмов, созданных с помощью искусственного интеллекта — AI Film Award. Главный приз в $1 млн достался короткометражному фильму «Лили» тунисского режиссёра Зубейра Эль-Джласси.
Это камерная и тревожная история об одиноком архивариусе, чья жизнь меняется, когда он находит куклу на месте ДТП. Фильм был создан с помощью инструментов от Google: генератор видео Veo отвечал за визуальный ряд, а Gemini использовался для создания раскадровок и поиска образов героев.
❯ Тема недели: Испытание «Аполлона-5»

22 января 1968 года на орбиту отправился самый странный аппарат в истории — Лунный модуль, похожий на паука из золотой фольги.
Это был первый раз, когда миссией полностью дирижировал компьютер, и он… облажался. Из-за излишней «осторожности» софта двигатель заглох через 4 секунды. Эта ситуация напоминает нам, что даже самый совершенный код — это всего лишь набор инструкций, лишенный интуиции.
Сегодня, обучая нейросети управлять автомобилями и принимать решения в медицине, мы сталкиваемся с тем же «синдромом Аполлона-5»: машина может быть технически права, но контекстуально бесполезна. Символично, что 58 лет назад именно человеческое вмешательство спасло технологию, напомнив нам: в любой системе финальный «Enter» всегда должен оставаться за человеком.
❯ Аудиоверсия дайджеста
❯ Заключение
Неделя получилась насыщенной: Google даёт Gemini копаться в наших личных фото и письмах, нейросети пишут операционные системы с нуля, а бум на искусственный интеллект уже взвинтил цены на SSD до 2027 года.
Искусственный интеллект всё глубже интегрируется в нашу жизнь — от анализа личных данных до создания фундаментальных программных продуктов. Это открывает невероятные возможности, но вместе с тем ставит новые экономические и этические вопросы, которые нам всем предстоит решать.
До встречи в следующем выпуске!
Показать полностью
11
5

Медицинская экспертная система: личный опыт и выводы о здоровье
Периодически возращаюсь к разработке медицинской экспертной системы. Несмотря на то что делаю за свои деньги и на своём железе, результаты уже очень хорошие по точности, loss и здравому смыслу. Датасет уже на десяток тысяч болезней и продолжаю наполнять.
И вот какие выводы при работе с этой системой. Если человек систематически курит или употребляет алкоголь (пусть и слабоалкогольное даже в 1 процент) больше 2 раз в неделю, то не нужно других причин заболеваний - это отражается на всех органах и на психике. Если избыточная масса или ожирение, то тоже нужно бороться с этими недугами, а уж потом с самой болезнью.
Если употребляют запрещённые вещества или пользуются "безопасными электронными вейпами" то даже можно не делать запрос в систему - впитываются сразу в кровь и искать другой источник не нужно. Медицинская экспертная система выдаёт в таких случаях почти идентичный ответ - злоупотребление веществами.
Масса болезней от того, что мы едим. Не от вида продуктов, а от того как они приготовлены и где приготовлены. То есть сырые продукты типа холодного копчения или суши это лотерея с однозначным итогом. В этот же кластер попадают кафе, рестораны, уличная еда - как бы там не соблюдали гигиену, у них большой поток посетителей, у которых медицинскую карту не спросишь, а они являются переносчиками заболеваний.
Соблюдая элементарные правила здорового образа жизни мы можем отсечь примерно 70 процентов болезней. Остальные проценты занимают вирусы и бактерии, плюс сложные заболевания причину которых или ещё не понимают или очень редкие заболевания. Такие заболевания требуют помощи профессиональных врачей.
И не знаю, есть ли у врачей такие системы поддержки решений на государственном уровне, только удержать в голове симптомы тысяч болезней это удел очень одарённых людей, причём симптомы большинства болезней одинаковы - температура, озноб, лихорадка, боль, отёк, покраснение и т.д. . Анализы выявят точный диагноз, но массовая медицина работает не так.
Даже простая система по диагностике ускорит определение диагноза болезни и упростит принятие решения по лечению. И ещё один мой вывод - зарубежными системами мы пользоваться не можем, необходим свой технологический суверенитет.
Показать полностью


Продолжение поста «Мне сегодня 7 годиков! (^o^)»1
✅ 100К рейтинга
Успел заскринить круглую цифру рейтинга 🤗

Чего ждать от ИИ в 2026 году?
Каждый день в мире выходят сотни исследований в области ИИ. За прошлый год вышло около 50 000 работ. Изучить все это невозможно, и главное — большая часть из них не влияет на реальный прогресс в ИИ.
На моем YouTube-канале вышло новое видео, в котором я проанализировал 30 самых перспективных исследований ИИ за прошлый год. Это позволяет понять текущие тренды и прогнозировать, что нас ждет в новом году.
Я разделил исследования на шесть ключевых направлений и разобрал их простыми словами. :
как меняются методы обучения моделей;
как строить работающие мультиагентные системы;
как ИИ воплощается в физическом мире в виде роботов и других устройств;
как ИИ влияет на программирование и науку;
и почему когнитивные системы и агентная экономика — следующий шаг в развитии ИИ.
Если вам важно не просто пользоваться ИИ или внедрять его в бизнес, а понимать, куда развивается сама технология и какую роль в этом играет человек — это видео для вас.
А какие из этих направлений вы считаете самыми перспективными в 2026 году?
Показать полностью
1


Что такое Deep Research агенты и зачем они нужны?

В свете недавнего выхода обновления Deep Research для Gemini стоит разобраться, как этот и подобные ему агенты работают.
Очевидно, что речь идет об автоматизированном поиске, вернее, о последовательности задач для поиска труднодоступной информации. Когда для получения финального решения проблемы необходимо пройти множество шагов по обнаружению и анализу данных, выполнить множество запросов, Deep Research может сократить время исследования до нескольких минут - по сравнению с часами, которые ушли бы на поиск в ручном режиме.
Многие AI-лаборатории - OpenAI, Google, IBM - имеют свои версии Deep Research агента. Но мы, тем не менее, знаем и его открытые его реализации, взять хотя бы Open Deep Research от LangChain. Последний дает хорошее представление об архитектуре - как и любой Deep Research пайплайн, он включает уточнение границ исследования, собственно поиск и формирование конечного отчета. Все это - хорошо знакомые мультиагентные сценарии, когда агент-супервайзер планирует конкретные поисковые задачи для агентов-исполнителей, вызывающих внешние функции. Основных проблем две: скорость выполнения задач и доступ к качественным источникам данных.
Скорость зависит от LLM - именно поэтому для агентных систем сейчас разрабатываются модели с высокой пропускной способностью, а также с упором на быстрый и точный reasoning. К этим разработкам относится недавний релиз первой модели нового поколения Nemotron 3 от Nvidia. Эта серия LLM была заявлена именно как вклад компании в развитие открытого агентного AI. Скорость инференса была повышена за счет гибридной архитектуры - трансформер плюс мамба, преимущества последней в отношении пропускной способности и экономного расхода памяти на KV-кэш хорошо известны. Впрочем, гибриды - не единственный путь для усиления агентных способностей AI. DeepSeek имеет очень выгодную для этого архитектуру, реализующую MLA-внимание (Multi-Head Latent Attention), которое обеспечивает высокопроизводительный инференс за счет очень малых, по сравнению с полным вниманием, расходов на KV-кэш.
Далее, мы сталкиваемся с проблемой, когда одна и та же реализация Deep Research дает очень разные результаты в зависимости от доступных данных. Для веб-поиска есть удобные, интегрируемые с AI агентами инструменты типа Tavily. Но далеко не на все вопросы можно получить ответы, просто “погуглив”. Для доступа к данным из частных источников, например, часто возникает необходимость деплоить Deep Research в приватное окружение. Я работаю с разными подходами к решению этой проблемы, включая облачные приватные эндпоинты, или собственный LLM-сервер, развернутый локально или в облаке. Все сводится к тому, как предоставить модели безопасный доступ к данным. Ответом может быть использование вашего собственного конфиденциального MCP-сервера, имеющего доступ к закрытым данным и реализующего определенный механизм авторизации для LLM, запрашивающим доступ к определенным частям этих данных (MCP-ресурсам). Например, если к LLM имеет доступ кто-то кроме вас, доступ не даем вообще или ограничиваем. Всегда можно запрашивать разрешение пользователя - владельца данных, что поддерживается протоколом MCP.
Наконец, необходимо совершенствовать поисковые способности открытых моделей. Крупные компании усиленно “качают” свои модели для повышения эффективности в многошаговых поисковых сценариях - например, Gemini 3 Pro, на котором работает их новый Deep Research агент. Основные вызовы, для достойного ответа на которые тренировали модель - улучшение качества финального отчета агента, в котором должны быть сведены к минимуму галлюцинации и должна присутствовать верификация выводов фактами из достоверных источников. Продуктом исследований Google стал углубленный бенчмарк DeepSearchQA, который может помочь и для улучшения открытых моделей, направленных на решение тех же задач. Преимущество этого бенчмарка - категоризация данных по различным областям исследований, их качество (примеры составлены вручную), и фокус на оценке не только правильности ответа, но и его полноте.
В итоге мы видим, что Deep Research - это агентный паттерн с широкой областью применения, который может быть востребован многими AI-системами. То, что нам нужно - это повышение надежности и автономности поиска, что зависит от факторов, рассмотренных выше.
Показать полностью